
The Rise of Agents, Part 1: The Three Walls
The frame problem fell to learning. The open-world problem fell to language. The third wall may not fall to anything we currently know how to build.


Agent research has built three kinds of agent in sixty years. Each kind got further than the one before. Each kind hit a wall. The third wall, which language agents are hitting now, is different from the first two. It is not a problem of technology. It is a problem of whether the technology is even pointed at the right thing.
This is Part 1 of a series about where agent capability is now, what determines its limit, and what happens if it is ever crossed. Today’s article lays down the map: three eras, three walls, one summit above them that remains untouched.
The Three Walls
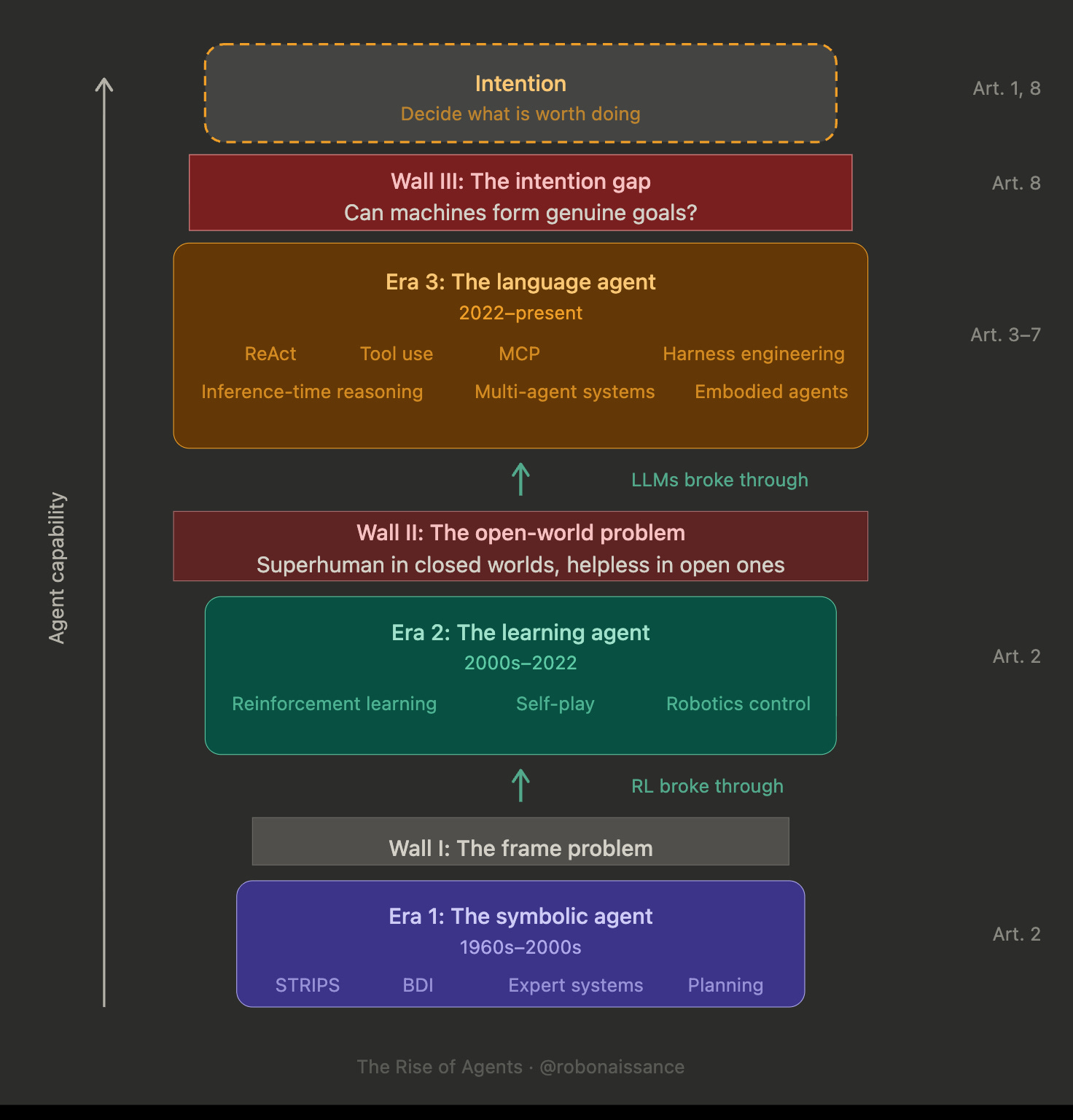
Three eras of agent research, each with a wall above it, and one summit still unreached. The diagram is the map for this entire series. Every article lands somewhere on it.
Era 1: the symbolic agent. 1960s to 2000s. STRIPS, planning systems, expert systems, logic-based agents. Agents built from explicit representations of knowledge and explicit rules for action.
Era 2: the learning agent. 2000s to 2022. Reinforcement learning, AlphaGo, robotics control. Agents built from optimization against reward signals, learning their own representations of the world through experience.
Era 3: the language agent. 2022 to present. ReAct, tool use, MCP, harness engineering. Agents built on top of language models, reasoning in natural language, acting through tools, orchestrating multi-step workflows.
The progression goes like this.
Symbolic agents hit the frame problem: they could not represent a world rich enough for useful action, because the representation cost grew faster than the world’s complexity.
RL broke that wall by learning representations instead of specifying them. But it hit a different one: the open-world problem. Systems that were superhuman in closed environments like Go were helpless in the open world, where the rules are not given in advance.
Language agents broke that wall by inheriting the open-world competence of models trained on almost everything humans have written. But they face a third wall.
The intention gap.
This is where the third wall stands, between agents that execute and agents that originate. Above the three eras, on the diagram, a dashed outline marks the region beyond it. No era has reached it. Whether any era ever will, and whether what we find when we get there will be an engineering problem or something deeper, is the question this series is built toward.
Era 1: The Symbolic Agent
Start with what a symbolic agent is trying to do. If you can write down facts about the world as logical propositions, you can have a computer reason over those propositions and derive actions that would change them into other propositions you prefer. The world becomes a symbolic structure. The agent becomes a process that searches through action sequences to transform one structure into another. This is the move that defines the first era of agent research, and it runs from the 1960s into the 1990s.
STRIPS, published in 1971 by Richard Fikes and Nils Nilsson at SRI, makes the approach concrete. An agent has a set of facts describing the initial state of the world, a set of operators describing possible actions, and a goal describing the desired state.
The planner searches through operator sequences to find one that transforms the initial state into the goal state. Every action has preconditions that must be true before it can apply, and effects that specify what changes afterward.
This is elegant. It is also how humans often describe their own planning, at least introspectively. “To get to the meeting, I need to be at the office, so I need to leave the house, so I need to find my keys.” Each step has preconditions and effects. The symbolic agent makes this structure computable.
For three decades, this is the dominant approach to agent research. Planning systems manage air traffic control, coordinate spacecraft operations, run military simulations. Expert systems capture human domain knowledge in rule form. Agent architectures like BDI, introduced by Rao and Georgeff in 1991, formalize how symbolic agents represent mental states. Each approach adds sophistication to the basic symbolic move: handling uncertainty, managing multiple goals, coordinating among multiple agents.
Then the approach hits a wall.
The First Wall
The frame problem is often stated as a narrow technical issue: how do you update a symbolic representation of the world after an action, without re-checking every fact? This framing understates the depth of the problem. What the frame problem reveals is that symbolic representation scales badly against world complexity. For a toy world with a hundred objects and a few dozen possible actions, you can enumerate the state space. For the real world, you cannot.
Symbolic agents inherit this problem whole. An agent can only plan over what it can represent, and it can only represent what a human has explicitly encoded. Rich knowledge bases become unmaintainable. Incomplete knowledge bases produce brittle agents that fail whenever they encounter a situation outside their representation.
By the late 1990s, the limitation is obvious. You can build a symbolic agent that manages a specific domain: an air traffic control system for a specific airport, a fault manager for a specific spacecraft. You cannot build a symbolic agent that can do something it has not been explicitly modeled to do. The frame problem has no engineering solution inside the symbolic paradigm.
Reinforcement learning offers a way through. Instead of representing the world symbolically and reasoning over that representation, you let the agent learn its own representation through interaction. Instead of specifying goals as logical conditions, you provide a reward signal, and the agent discovers what behavior produces reward.
This is a philosophical shift. Where symbolic approaches make everything explicit and legible, RL makes everything implicit and opaque. The representations are learned patterns in neural network weights. The planning is folded into the policy. The goals are buried in the reward function. The cost of this opacity will not be fully felt for another two decades.
Era 2: The Learning Agent
The learning agent era produces spectacular results in closed environments. AlphaGo defeats Lee Sedol in 2016. Three years later, AlphaStar plays StarCraft II at the professional level. Robots learn to grasp objects through simulation, to walk through reinforcement learning, to manipulate complex tools through self-play. The symbolic limitations of the previous era look like historical artifacts. The learning agent is the new paradigm.
The central insight of reinforcement learning is that agents can discover high-performance behavior through trial and error with reward feedback, without a human having to program the solution. Instead of telling the agent how the world works, you let it try things and learn. The result is agents that can master tasks no human can hand-specify: finding non-obvious strategies in Go, producing fluid locomotion in simulated robots, playing Atari games from pixel input alone.
For a decade, it looks like the learning agent will eat the world. Every task can be framed as an RL problem. Every problem can be solved by scaling up simulation and compute.
The Second Wall
Then it hits a different wall. Learning agents are superhuman in environments where the rules are given in advance, the environment is simulable, and the reward signal is clean. They are helpless in environments without these properties, which is to say, in the open world.
Consider the gap between AlphaGo and an agent that can book you a flight. AlphaGo handles a state space of roughly 10^170 positions, more than the atoms in the observable universe, and it handles them superhumanly. Booking a flight requires understanding what a user wants, navigating websites that were not designed for agents, handling authentication, parsing dynamic content, and making judgment calls about trade-offs the user has not explicitly specified. The state space is far smaller. But the task is beyond any pure RL system.
The reason is that RL has purchased its performance by assuming a fixed, well-specified task structure. In Go, this works. The rules do not change. The reward is clean. The environment is fully simulable.
In the open world, none of these assumptions hold. A flight-booking task changes based on user preferences that are not known in advance. The reward depends on user satisfaction that cannot be measured during training. The environment cannot be simulated at the fidelity needed.
Era 1 was defeated by what it could not represent. Era 2 is defeated by what it cannot simulate. Different walls, different paradigms, same pattern. Each era buys its capability by making assumptions about the world that work inside the paradigm and break when the paradigm meets reality.
Era 3: The Language Agent
The language agent era begins, debatably, with the 2022 ReAct paper, which shows that large language models can be made to reason in natural language about tool use. A model is prompted to produce an interleaved sequence: thoughts about what to do, actions to take, observations from those actions, more thoughts. The loop is recognizable. Deliberate, act, observe, deliberate again. But the technology underneath is something no previous era had access to.
Language models have been trained on almost everything humans have written. This means they have, encoded in their weights, an implicit model of how humans reason about goals, obstacles, plans, and trade-offs.
You do not need to specify beliefs in advance, because the model brings its training distribution’s worth of world knowledge with it. You do not need to solve the frame problem, because the model operates on tokens rather than logical predicates and has learned from text what tends to stay constant across contexts. You do not need the environment to be simulable, because the model has already read descriptions of most environments humans operate in.
This is why Era 3 works where Era 1 and Era 2 failed. The two walls that stopped the earlier eras are not walls for language agents. The frame problem dissolves into tokens. The open-world problem dissolves into training data. The engineering questions that defined decades of agent research become, at least in their basic form, solved.
Current agents can do things no agent could do five years ago. They can navigate websites. They can write and debug code. They can chain tool calls across dozens of steps. They can recover from errors. They can maintain goals across long conversations. The field is in the middle of its most productive period in its sixty-year history.
And yet something is missing.
The Summit
So where is the wall? If language models give us open-world competence and natural language gives us runtime goal specification, what is left unsolved?
Here is what all three eras of agent research have in common. They all assumed the agent’s goals were given. STRIPS planners were given goal conditions. RL agents were given reward functions. LLM agents are given prompts. In every case, the intentionality originated outside the agent.
The agent’s job, across sixty years of research, has been to translate external specifications into coherent action. That is translation. Origination is something else.
No agent has ever originated its own goals in the way a person does. This is not a statement about the agent’s capabilities. A sufficiently capable agent could simulate originating its own goals: generate plausible-looking preferences, commit to them, act on them. The question is whether the agent is generating goals or performing the appearance of generating them. Whether there is anything inside that wants.
The diagram marks this at the top. Above the three eras of walls sits a region labeled Intention: the capability to decide for oneself what is worth doing. No era has reached it. The third wall, the intention gap, is the distance between the engineering work that has defined three eras and that region above.
Call the wall the intention gap, call the region above it Intention, call it what you will. The names matter less than the structure. There is engineering work, and there is something above it, and between them is a distance nothing in the agent stack currently knows how to close.
This is not a critique of current agents. It is a recognition of what they are. They are extraordinarily capable execution surfaces for human intention. They are not sources of intention. When you instruct an agent to “find me a flight to Tokyo,” the intention to find the flight is yours. The agent executes. It does not want the flight. It does not prefer Tokyo over Osaka. It is a sophisticated executor applied to your intention.
The deeper question is whether an agent could, in principle, originate intention. Whether the distance is one that will close with enough scaling and architectural improvement, or a distance of a different kind: a boundary that engineering cannot cross because what is missing is not a technique. Whether agents will become sources of intention, whether that is technically possible, whether it is desirable, whether we would recognize it if it happened.
These are the questions this series aims toward.
What the Series Will Do
The Rise of Agents is eight articles, mapping the terrain across three eras and probing what lies at the top.
Articles 2 and 3 return to the lower walls, examining how RL and ReAct together made the current paradigm possible. Articles 4 through 7 map the space above the second wall: harness engineering, inference-time reasoning, multi-agent systems, embodied agents. Article 8 closes with the summit itself. What the intention gap is, what it would mean to cross it, and whether we should want to.
The next article is about the second wall. RL has not been replaced by language agents. It has been absorbed into them. The story of what happened to reinforcement learning when language agents arrived is how we understand what language agents actually are.
For now, hold the diagram in mind. Three eras, three walls, one summit we have not reached. That summit is where we are going. The first two walls are why we believe getting there is possible. The third wall is why we cannot be sure.
The Rise of Agents is an eight-part series. Next, Part 2: “What Language Agents Inherited.”
I haven't read all the articles in the series, just this one, so maybe it is answered in a later one.
I wonder, how well can current AI recognize intent?
When a person sees another person lift a cup to drink from it, it is usually easy for us to determine what they intend to do before they do it. Are AI systems able to do something like that?
To the man with a hammer, everything looks like a nail. Most of his friends work with hammers. He reads thinkpieces about the impact of hammers and even attends hammer conferences.
The field of hammers is developing rapidly. There are now agentic hammers that autonomously bang anything nail-shaped. The remaining limitations of hammers, he reads, are almost solved, and the General Hammer is imminent.
Sometimes, on a clear quiet night, when the breeze lands just right, he allows himself to wonder. Is there something missing? Why all the hammering in the first place? Could it be that the dominance of the "hammer gaze" is why the world itself seems to require ever-more hammers? What is the true cost?
He dimly recalls having once heard of a form of carpentry that doesn't need nails at all, let alone hammers. But none of his friends seem to have such doubts, or if they do, they hide it as well as he does.
Besides, hammers are where the money is. And there are many very smart and well-paid people working on hammers. Perhaps we should just leave the "why" to the philosophers.