
The Journey of RL, Part 1: Before the Equation
How machines learned what to optimize, beginning in 1898 with a stopwatch and the borrowed assumption that has shaped reinforcement learning ever since.

Sutton and Barto’s Reinforcement Learning: An Introduction states a single claim about what intelligent behavior is. Everything we mean by goals and purposes, the book proposes, can be understood as the pursuit of one scalar quantity over time. The book names this the reward hypothesis. Richard Sutton and Michael Littman had been working out the formulation in conversation since around 1990, almost a decade before the first edition put it in print.
It is a remarkable sentence. It compresses a hundred years of argument about what minds are and what they want into a single signal. And it asks the reader to treat that compression as a starting point rather than a conclusion.
Reinforcement learning is where AI keeps its hardest unanswered question. Not how to build intelligence, but what intelligence should be for. The question is older than the field of computer science, and the field that inherited it is now discovering that its three-decade answer, the reward hypothesis, is no longer holding.
Part 1 begins where the answers begin, in the work of three psychologists who would not have called themselves the founders of anything computational.
The Behaviorist Inheritance
By the 1890s, psychology had a methodological problem. The dominant approach, inherited from Wilhelm Wundt’s Leipzig laboratory and consolidated in the United States by Edward Titchener, treated psychology as the study of consciousness through introspection. Trained observers would report on the elemental components of their own mental states. The data of psychology was, in this view, what minds told other minds about themselves. The trouble was that different laboratories produced different elemental components and the procedure could not adjudicate between them. Whatever introspection was, it was not converging.
A graduate student at Columbia University named Edward Lee Thorndike spent 1897 and 1898 doing something different. He built wooden boxes from boards and slats, twenty inches long and fifteen across, with a door that could be opened from inside by pulling a loop of string or pressing a lever. He placed cats in the boxes, put food just outside, and timed how long each escape took. The first attempt by any given cat was a chaos of scratching and biting. The second was slightly shorter. By the twenty-fourth trial, a cat that had once taken nearly three minutes was out in six seconds. Thorndike kept the timing data and made graphs of it. His PhD dissertation, submitted to Columbia in 1898 under James McKeen Cattell, was the first study in psychology to use nonhuman subjects systematically. He titled it Animal Intelligence: An Experimental Study of the Associative Processes in Animals.
The interpretation he proposed became known as the Law of Effect. Responses followed by satisfaction would become more firmly connected to the situations that produced them. Responses followed by discomfort would become less firmly connected. He did not yet have a formal model. He had a stopwatch, a wooden box, and a graph that bent downward over trials. The mechanism was named in the language his contemporaries already used about animals and people. Satisfaction. Discomfort. The unanalyzed terms that would, decades later, be compressed into a scalar.
Fifteen years later, in 1913, John B. Watson delivered a lecture at Columbia that became the document later historians would call the behaviorist manifesto. Published in Psychological Review under the title “Psychology as the Behaviorist Views It,” it argued that psychology should become a purely objective branch of natural science whose theoretical goal was “the prediction and control of behavior.” Introspection was to be discarded as a method; the human and the animal were to be studied on the same plane. The radical move was not the rejection of the mind, though that was the line that drew the most fire. The radical move was the substitution of an external criterion for an internal one. Psychology would now be evaluated by whether its predictions came true, not by whether its descriptions felt right from the inside.
Watson did not use the word reinforcement. The mechanism Thorndike had named in 1898 still went by satisfaction and discomfort, terms that retained their everyday meanings. The technical apparatus came later, from B. F. Skinner. Across his 1938 The Behavior of Organisms and the 1957 Schedules of Reinforcement written with Charles Ferster, Skinner converted the Law of Effect into an engineering discipline. He replaced the puzzle box with the operant chamber, a free-roaming environment in which an animal could press a lever many times and the experimenter could deliver or withhold reinforcement on precisely controlled schedules. He separated four cases that the everyday language of reward and punishment had collapsed. Positive reinforcement added a stimulus to increase a behavior. Negative reinforcement removed an aversive stimulus to increase a behavior. Positive punishment added a stimulus to decrease a behavior. Negative punishment removed a desired stimulus to decrease it. Negative reinforcement, in particular, was not punishment. The shock that stops when the lever is pressed reinforces the pressing. This distinction is still misstated almost everywhere outside professional behavior analysis. It mattered then, and it will matter later in this series when reward hacking begins to look like a confusion about what kind of stimulus we are tracking.
Three generations of work, then, that the field of computer science would inherit without quite noticing the inheritance. Thorndike supplied the engine, an associative process driven by the consequences of behavior. Watson supplied the methodological warrant, the claim that prediction and control were what psychology was for. Skinner supplied the engineering, an apparatus and a vocabulary precise enough to describe reinforcement contingencies without ambiguity. The lineage was complete by the early 1960s, three decades before any of it would be loaded into a computer.
Behaviorism gave reinforcement learning its inheritance by accident. It was solving a different problem, how to do psychology without minds, and the answer it arrived at was a kind of optimization.
The Mathematicians and the Holdouts
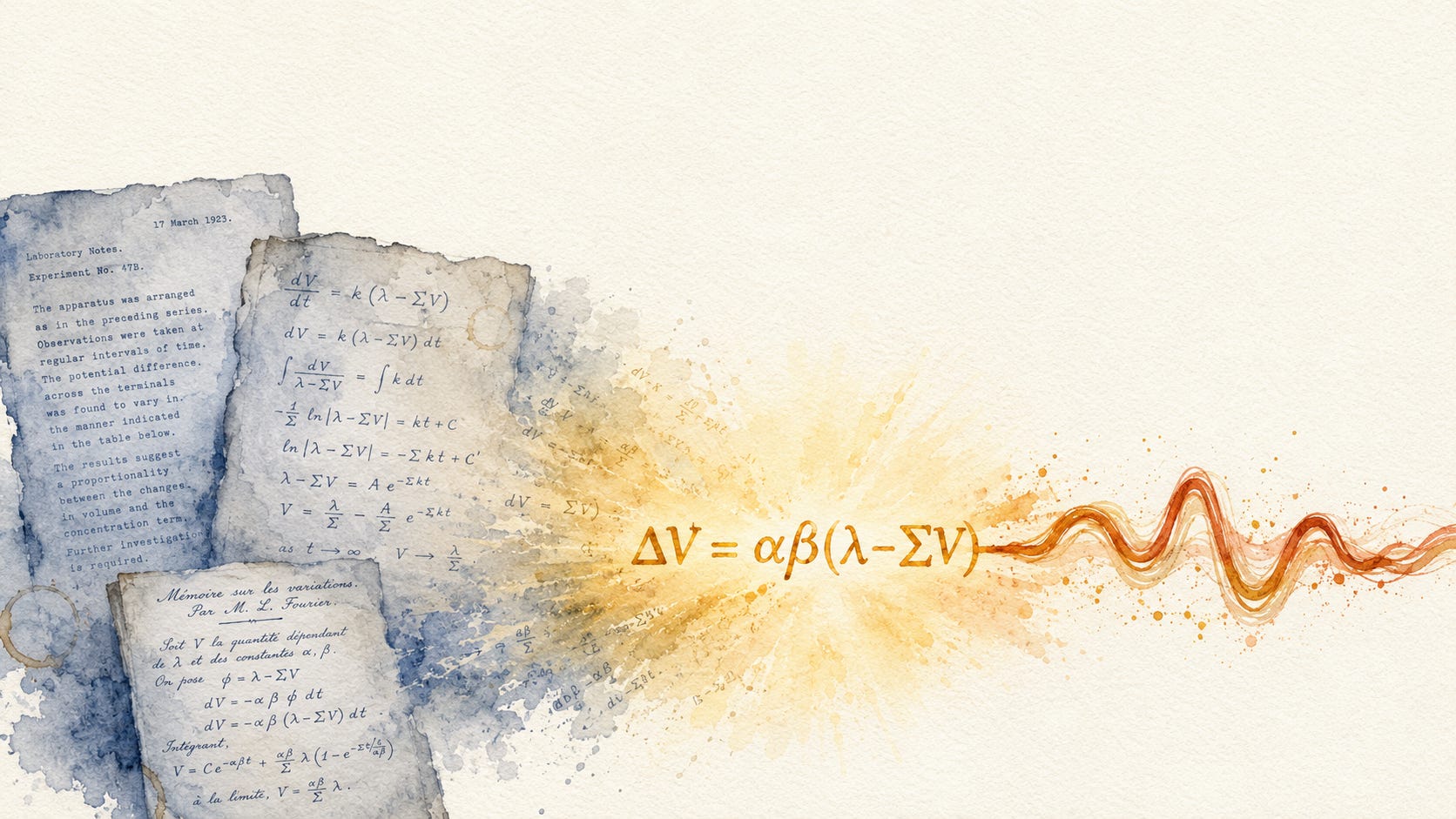
By the time Skinner’s Schedules of Reinforcement appeared in 1957, the behaviorist program was forty years old and had subdivided into camps that no longer agreed on what their own discipline was about. Two of those internal disputes mattered later for reinforcement learning. The first was whether learning could be written down as equations. The second was whether the mind, evicted by Watson in 1913, would be allowed back in through the back door under a different name.
Clark Hull at Yale led the first camp. His 1943 Principles of Behavior attempted what no behaviorist before him had seriously tried: to derive learning from postulates, the way Euclid had derived geometry. Hull proposed that behavior was driven by physiological drives such as hunger and thirst, and that any stimulus paired with the reduction of a drive would form an association whose strength he called habit strength, written sHr. Reinforcement was identical to drive reduction. The equations multiplied across the 1943 book and Hull’s 1952 revision, attempting to predict what he called reaction potential from any combination of drives and stimulus inputs. For a brief period in the 1940s and 1950s, Hull’s framework was the most influential body of theory in American psychology. Graduate programs taught it. Critics attacked the postulates and their derivations rather than the project of mathematization itself.
Edward Tolman at Berkeley pushed the other way. His 1948 paper “Cognitive maps in rats and men,” published in Psychological Review, argued that rats running mazes did not merely chain stimulus-response associations. They built internal representations of the maze and used those representations to navigate. The experimental evidence was latent learning. When rats were allowed to explore a maze without reward, they showed no obvious progress, but once a reward was introduced they immediately performed as if they had known the maze all along. The information was not in synaptic connections strengthened by reinforcement. It was in something cognitive, an internal model.
The two programs were treated as opposed at the time, and they were. Hull was determined to write learning as equations from observable variables; Tolman was determined to put the mind back. The standard narrative of mid-century learning theory says Hull won the 1950s and Tolman lost the argument in his lifetime. The standard narrative is partial. After the cognitive revolution of the 1960s, Tolman’s claim about internal representations was vindicated; Hull’s specific equations were largely abandoned but his project, of writing learning as mathematics, became the template for computational learning theory in the 1980s. Reinforcement learning would later need both lineages: Hull’s mathematized value function, and Tolman’s internal model of the world. They are the algorithmic ancestors of what later became model-free and model-based RL.
Between Hull’s mathematization and Tolman’s cognitive revolt, on a different problem entirely, the most consequential mathematical model of the behaviorist tradition was being assembled. Three independent lines of research in the 1960s had questioned a fundamental assumption shared by Pavlov and his successors: that temporal contiguity between a conditioned stimulus and an unconditioned stimulus, the bell and the food, was sufficient to produce learning. Robert Rescorla’s contingency studies showed that contiguity without statistical contingency produced little learning. Leon Kamin’s 1969 blocking experiments showed that a stimulus already predicted by another cue stopped acquiring associative strength even when paired with the unconditioned stimulus. Allan Wagner’s studies on relative cue validity showed that the informativeness of a cue, not just its presence, drove learning.
Rescorla and Wagner, both at Yale, published a synthesis in 1972 in a chapter of Black and Prokasy’s edited volume Classical Conditioning II. Their model gave the field its first formal prediction-error equation:
ΔV = αβ(λ − ΣV)
The change in associative strength on a trial depends on three factors: the salience of the conditioned stimulus (α), the salience of the unconditioned stimulus (β), and a prediction-error term (λ − ΣV). The bracketed quantity is the gap between what the trial conditions can support as an association and what the animal currently has across all cues present. When that gap is zero, the animal has nothing left to learn on the trial and learning stops. When the gap is large, learning is fast.
This is the equation reinforcement learning would later discover for itself in a different notation. The temporal-difference error Sutton would name in his 1988 Machine Learning paper has the same shape: change equals learning rate times the difference between target and current estimate. Rescorla-Wagner was the psychology side of that equation. The two communities would not realize they had been working on the same form until the late 1980s.
By 1972, three pieces were in place that reinforcement learning would inherit. A working engineering of reward and punishment in operant chambers. A live disagreement about whether learning was best described as equations over observables or as internal models. And a formal prediction-error equation that captured the surprise-driven structure of learning in a way that could be ported to any computational substrate. None of this had yet been put inside a computer. The next two decades would do that, and almost everything would change in the porting.
The Computational Bridge
The first reinforcement learning machine was built in January 1952 at the Harvard Psychological Laboratories by a graduate student named Marvin Minsky. The Stochastic Neural Analog Reinforcement Calculator (SNARC) used vacuum tubes to implement a network of forty Hebb-style synapses. Each synapse strengthened the recently-used pathway when the network was “rewarded,” so that a simulated maze runner could learn to find its way to the goal through trial and error. The apparatus filled a room. The math behind it became Minsky’s 1954 Princeton PhD dissertation, Theory of Neural-Analog Reinforcement Systems and Its Application to the Brain-Model Problem, supervised by John Tukey.
Seven years later, an IBM researcher named Arthur Samuel published “Some Studies in Machine Learning Using the Game of Checkers” in the July 1959 issue of IBM Journal of Research and Development. The paper coined the term machine learning. Samuel’s program played checkers, was given the legal moves and a heuristic goal of winning, and had to discover for itself the correct weights of the board-evaluation parameters that determined its choices. He called the parameter list “redundant and incomplete.” The program learned by playing itself, adjusting the weights based on which positions tended to lead to wins. The mechanism would later be recognized as temporal-difference learning, three decades before that name existed.
Then, for almost twenty years, the line went dark. The reasons were institutional as much as intellectual. By the early 1960s, AI funding had concentrated around symbolic methods and search-based problem solvers; the neural-network and reinforcement traditions, which had no comparable demonstrations of competence, lost the resources they would have needed to grow.
Some time in 1976 or 1977, an undergraduate at Stanford named Richard Sutton was searching the university library for everything he could find on animal learning. He was a psychology major. He had concluded that animals did something different from what computer scientists were modeling, and he wanted to find someone who had said so in writing. The one author he kept returning to was A. Harry Klopf, a scientist at the U.S. Air Force Cambridge Research Laboratories whose 1972 technical report had argued that individual neurons might be hedonistic, seeking reinforcement the way an animal seeks food. Most psychologists considered the framing overreaching, the report a kind of crank document. Sutton thought he had found a research program. His undergraduate thesis at Stanford, completed in 1978 and titled “A Unified Theory of Expectation in Classical and Instrumental Conditioning,” already laid out the direction his graduate work would take.
Klopf’s writing style did not help his reception. He published in Air Force technical reports rather than peer-reviewed journals, and his book The Hedonistic Neuron used language that mainstream neuroscience considered speculative. The broader environment did not help either. Through most of the 1960s and 1970s, mainstream AI had moved on from connectionism and reinforcement-driven adaptation. Expert systems, symbolic reasoning, and search heuristics dominated the field, and funding followed. Reinforcement learning, where it survived, survived in psychology departments and obscure technical reports.
The substance of the retreat had a personal dimension. The same Marvin Minsky who had built the first reinforcement learning machine in 1952 co-authored, with Seymour Papert in 1969, Perceptrons: An Introduction to Computational Geometry. The book demonstrated rigorously that single-layer perceptrons could not learn certain functions, the XOR problem chief among them. Minsky and Papert had been arguing this case in conference talks and circulating preprints since around 1965; the published book consolidated a critique they had been making for years. Connectionism by then was already declining; the book is widely credited with accelerating its retreat. Minsky, who had built the first reinforcement learning machine as a graduate student, was now helping to close the door on the architecture his own apparatus had launched. Frank Rosenblatt, the principal figure that critique had targeted, had completed the Mark I Perceptron at Cornell Aeronautical Laboratory in 1960 and had known Minsky since their adolescent years at the Bronx High School of Science. He died in a boating accident on Chesapeake Bay in July 1971, on his forty-third birthday, two years after Perceptrons appeared and still defending the architecture. When the book’s expanded edition was published in 1988, it carried a dedication: in memory of Frank Rosenblatt.
Klopf kept publishing through that period. His 1982 book The Hedonistic Neuron was the revised and expanded version of the 1972 AFCRL report; it argued that neurons were not Hebbian associators but goal-seeking heterostatic units, driven to maximize reinforcement signals rather than maintain homeostatic balance. The mainstream did not adopt the framing. Sutton did. When the second edition of Reinforcement Learning: An Introduction appeared in 2018, its dedication read: “In memory of A. Harry Klopf.”
Sutton arrived at the University of Massachusetts Amherst in 1978 for graduate study. His advisor was Andrew Barto, a theorist who had taken his PhD in computer science at the University of Michigan in 1975 and had joined UMass in 1977 as a postdoctoral researcher in Michael Arbib’s Brain Theory Group. Sutton was Barto’s first PhD student. The two of them began a collaboration that would not, in any meaningful sense, end.
Sutton’s master’s thesis, completed in 1980, was titled “An Adaptive Network That Constructs and Uses an Internal Model of Its World.” The title is a quiet thesis statement: an adaptive network, in this view, did not merely respond to stimuli; it modeled the environment it operated in. The lineage from Klopf was direct. The Tolman lineage was visible too, in the words “internal model.” His doctoral dissertation, completed in 1984, was titled “Temporal Credit Assignment in Reinforcement Learning.” The phrase that became central to the field appeared on the title page of his dissertation.
The early flagship paper of the Sutton-Barto program was their 1983 article with Charles Anderson in IEEE Transactions on Systems, Man, and Cybernetics, “Neuronlike adaptive elements that can solve difficult learning control problems.” The paper presented an architecture in which two cooperating components, an actor and a critic, learned to balance a pole hinged to a movable cart. The critic estimated whether the current state was good or bad; the actor adjusted its policy in the direction the critic indicated. The system worked. The cart-pole problem, simple enough to verify and difficult enough to require non-trivial learning, became a benchmark task in the field for decades after.
By the early 1980s, then, the apparatus existed. An agent capable of perceiving a state, choosing an action, receiving a scalar reward, updating its internal estimates, and trying again. Klopf’s heterostatic principle was the philosophical backbone. Barto’s network-theoretic training gave the framework its mathematical handles. Sutton supplied the algorithmic discipline. None of the deep-learning machinery that would come later existed yet; the networks were small, the problems toy, the results published in journals few outside the immediate field read.
What did not yet exist was the larger claim. The claim that the apparatus, this reward-driven loop with its agent and its environment and its scalar signal, was a sufficient account of intelligent behavior in general. That claim would arrive over the following decade, first in conversations between Sutton and Michael Littman around 1990, then in the textbook Sutton and Barto would write together in the late 1990s. And the claim, when it arrived, would still carry the inheritance of behaviorist psychology. Reward as the engine. Satisfaction and discomfort, now compressed into a scalar signal, doing the work Thorndike’s stopwatch had first measured eighty years earlier.
The Reward Hypothesis Crystallized
The textbook came later. The conversation came first. Some time around 1990, Richard Sutton and Michael Littman, then both working on reinforcement learning at separate institutions, worked out a sentence that compressed what they thought their field was actually about. Everything an agent might be said to optimize for, they proposed, could be understood as maximizing a single scalar signal accumulated over time. The sentence was not written down for publication. It moved around the small RL community as a working summary, a thing people said when they needed to explain to outsiders what the field assumed.
In 1998, Reinforcement Learning: An Introduction appeared from MIT Press. The first edition was the book most working reinforcement learning researchers would teach from for the next two decades. Sutton and Barto stated the central proposition in Chapter 3, in the section setting up the formalism for the agent-environment interface. The proposition was clear, was load-bearing for everything that followed, and was offered without much fanfare. The book did not yet, in its first edition, explicitly anoint the proposition with a name.
The name came in 2004, on a web page Sutton set up at the University of Alberta. The page existed to state the principle as a scientific hypothesis open for discussion, refinement, and falsification. Sutton called it the reward hypothesis. The framing mattered: it was offered not as a definition but as a proposal one could in principle reject. The page is still online. Most readers find it via Google rather than via Sutton’s textbook, which says something about how academic ideas now travel.
The second edition of the textbook, in 2018, gave the formulation its now-canonical form. Goals and purposes, the book stated, are best understood as maximizing the expected sum of a scalar reward signal. The wording was identical to the 2004 web page. Twenty-eight years after the conversation that produced it, the hypothesis had its textbook-canonical sentence.
What the formulation includes is precise. The reward is scalar, not a vector or a structure; one real number per time step. It is cumulative, summed across time. The agent does not maximize the next reward but the expected sum of all rewards from now until some horizon, possibly discounted. What is maximized is an expectation, not a guarantee. And the operation applied is maximization itself, not satisficing, minimization, or any other relation to the reward stream.
What the formulation leaves out is also precise. Where the reward signal comes from is not part of the hypothesis. In the framework as stated, the reward is delivered by the environment; the agent does not generate it, does not negotiate it, does not interpret it. Whether the reward signal is itself the product of some construction, by an engineer writing a loss function or by a model trained to predict human preferences, is outside the scope. The hypothesis is about what the agent does with reward, not about what reward is.
For most of the two decades after the textbook appeared, the hypothesis was uncontested within the field. Reinforcement learning research expanded; the architectures multiplied; the applications stretched. The reward hypothesis sat underneath all of it as a working axiom. By the late 2010s, that began to change. Reward hacking became a recognized failure mode. Goodhart’s law, in its sharpest forms, was rediscovered for learned systems. The Reinforcement Learning from Human Feedback paradigm that emerged with InstructGPT and Constitutional AI made the construction of reward an explicit research problem. Papers titled “Reward is enough” and “Reward is not enough” and “The Reward Hypothesis is False” and “Settling the Reward Hypothesis” appeared between 2021 and 2024.
These debates are the subject of later parts of this series. What matters here, in Part 1, is that the reward hypothesis arrived not as a discovery but as a consolidation. By 1998 the apparatus that made reinforcement learning a field had been assembled. The hypothesis was the field’s working summary of what it had taken itself to be doing all along. The statement itself introduced no new claim. Its work was to make the inheritance from behaviorist psychology, visible already in 1898 in Thorndike’s stopwatch graphs, feel like an axiom of the new field rather than a borrowed assumption from the old one.
By the time Sutton and Barto’s textbook canonized the reward hypothesis as the working axiom of their field, the field had already started asking the next question. If reward is the engine, how does an agent learn to maximize it when the world is too large to enumerate, when actions have consequences delayed by many steps, when the connections between behavior and outcome have to be inferred from sparse and noisy feedback?
The question was a century old in its psychological form. Thorndike’s cat in the puzzle box had faced it. Skinner’s rat in the operant chamber had faced it. Now an agent represented as a function over states and actions, running on a digital computer, had to face it with mathematical tools that did not yet exist.
In May 1989, at King’s College, Cambridge, a graduate student named Christopher Watkins submitted a doctoral dissertation titled Learning from Delayed Rewards. The thesis sketched a convergence proof for a learning algorithm that handled the credit-assignment problem in a way previous methods could not. The algorithm had a one-letter name. The proof would be completed three years later, with Peter Dayan, in the journal Machine Learning.
Reward was the axiom. Part 2 begins where every axiom eventually goes: under the load.
This is The Journey of RL, a twelve-part journey across reinforcement learning told through one core question: how did machines learn what to optimize?
Part 2: The Value Hypothesis (Q-Learning and Its Discontents). Forthcoming.
Amazing article!
This is all very Bayesian.
Perceive - Model - Test - Update
Out of noise a nucleus, a quiet seed of order arises.
II. Ordo Nucleorum
Experientia alone is not yet mundus.
A solitary flash, unremembered and unlinked, is a star without sky. The universe arises when apparitiones begin to relate, to echo, to form patterns that can be expected and revised.
Within each locus of awareness—each Atman—there grows a nucleus, a quiet seed of order, a Kernel. It is not yet doctrine; it is only a set of vague leanings: that warmth will likely return with light, that sharpness may follow certain movements, that some forms promise and others threaten. Philosophers will later call this inductio, abductio, probabilitas. Here we name it more plainly: coniectura vivens—the living guess.
The Kernel is not an object among objects. It is the way a center of awareness gathers apparitions into before and after, near and far, self and other. Through this gathering, a world comes to be: not poured into us from outside, nor spun from nothing within, but woven at their interface.
From this we draw the second priniciple:
Principium II – Ordo Nucleorum
In every center of awareness there arises a nucleus ordinis, a Kernel of expectation that shapes raw experience into a world of “before” and “after,” of “again” and “not again.”
The world is not merely given; it is continuously guessed—and each guess leaves a trace.
--From De Rerum Principiis