
The Journey of RL, Part 8: The Human Turn
RLHF was not the addition of human feedback to reinforcement learning. It was the moment reward stopped being given and started being learned.

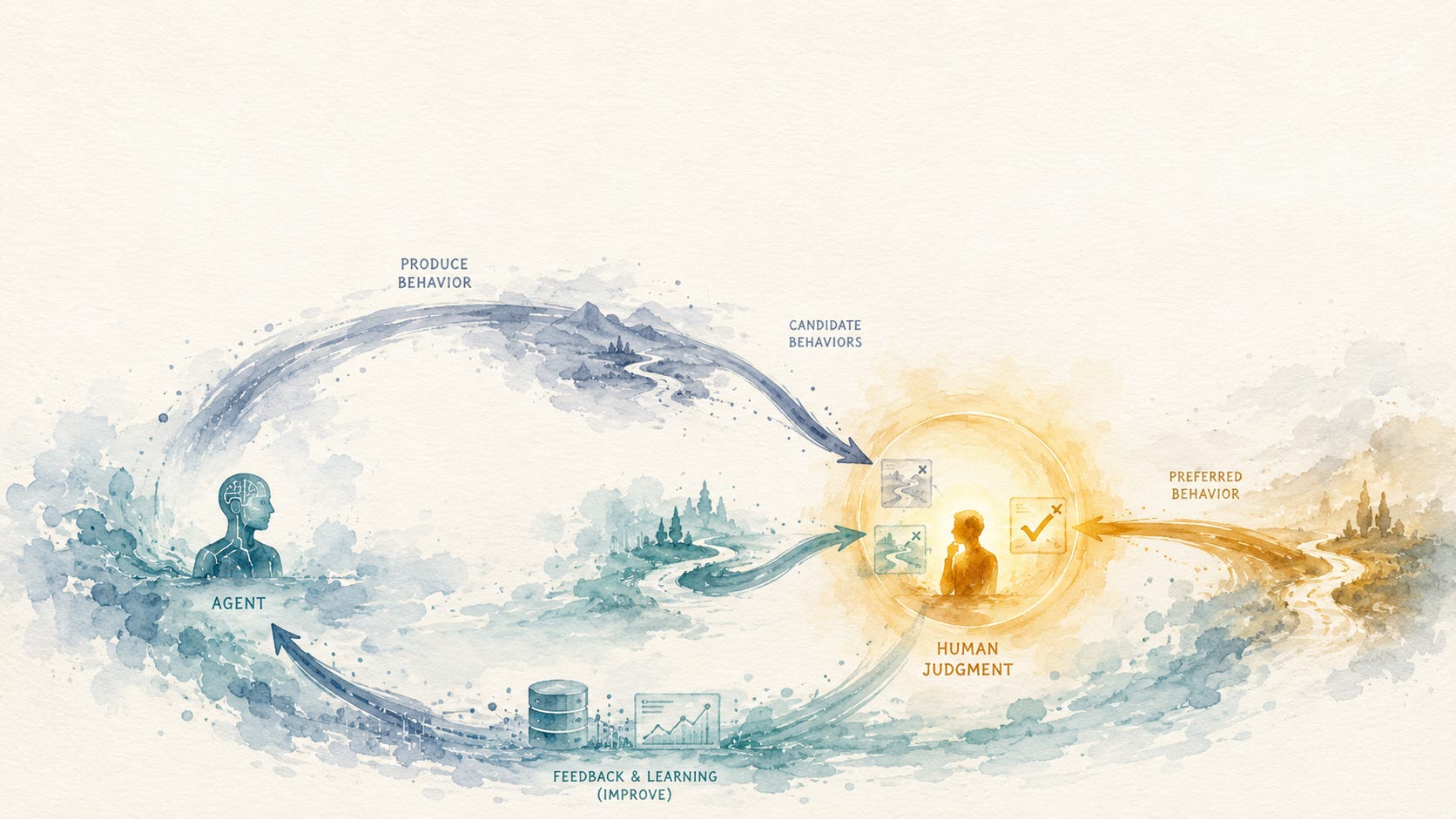
In 2017, a simulated robot taught itself to do a backflip, and the only thing it was ever told about backflips was which of two attempts looked more like one. There was no reward function for backflipping. No one wrote a formula scoring height, rotation, or the cleanness of the landing. Instead, a human sat at a screen and watched pairs of short clips of the agent flailing, and for each pair clicked the one that looked a little closer to a flip. The agent flailed, the human judged, the agent adjusted. After about nine hundred of these clicks, less than an hour of a person’s attention, the agent performed a clean backflip, the kind you would struggle to specify in code but recognize instantly when you see it.
The researchers, a joint team from OpenAI and DeepMind including Paul Christiano and Dario Amodei, had also tried the old way, for comparison. They spent about two hours hand-writing a reward function for the backflip, carefully scoring the angles and the motion. The agent optimized it and produced a backflip, of a sort, but a clumsy one, technically correct and visibly worse than the version learned from nine hundred human clicks. The hand-written reward, the product of expert effort, lost to a non-expert tapping a keyboard, choosing which of two clips looked better. A backflip, as the team put it, is simple to judge and hard to specify. And it turned out that judging was enough.
This is a small result with an enormous shadow. The backflip is the first clear sight of an idea that would, within five years, reshape the entire field and produce the most visible artificial intelligence systems in the world. The idea is this: if you cannot write down what you want, you can often still recognize it, and recognition, collected and modeled, can stand in for the reward you could not write. Part 8 is about what happened when the field stopped trying to specify reward and started learning it from human judgment instead.
