
The Making of DeepSeek
Ten years of quant infrastructure built the foundation. R1 made the company global. V4 extended the pattern. The original refusals are starting to bend.


Open the chat interface at chat.deepseek.com. Sign in with an email address. The account is free. No consumer subscription tier. The interface offers two modes: an Instant Mode powered by DeepSeek-V4-Flash and an Expert Mode powered by DeepSeek-V4-Pro, the lab’s frontier model at 1.6 trillion total parameters and 49 billion activated per token. The same Pro weights are downloadable from Hugging Face under MIT License. Anyone with the hardware can run the model the chatbot runs. The training paper is published. The lab that produced the model has roughly two hundred and seventy people on its research and engineering team and forty-eight in business and compliance. The founder has not given a major media interview in twenty-two months.
The lab operates from Hangzhou, in office space next to High-Flyer, the quantitative hedge fund whose founder is also the founder of DeepSeek. The author list on the V4 technical paper runs to two pages. Most of the names belong to fresh graduates from Peking University and Tsinghua University, or to researchers within a year or two of completing their degrees. Most have not worked anywhere else. There is no chief technology officer. There are no formal performance reviews. Each researcher can use the training cluster without approval; division of labor across people is determined by interest. The most consequential architectural innovation in DeepSeek’s first two years was multi-head latent attention, and it came from a single researcher’s idea rather than a top-down assignment. When V4 launched on April 24, 2026, the release consisted of a Hugging Face upload, a technical report PDF, and a routine update to the API documentation. There was no press conference, no demo application, no founder blog post. The model became available; the company did not stage a launch.
As of late April 2026, DeepSeek has just shipped its first major architectural release in fifteen months. V4-Pro and V4-Flash launched on April 24. The lab’s V4 paper introduces a hybrid attention mechanism that runs at twenty-seven percent of the compute of its predecessor at million-token context, alongside two additional architectural innovations the broader field has barely registered. Three days later, on April 27, the company filed an equity restructuring that raised registered capital by fifty percent and increased founder Liang Wenfeng’s direct stake from one percent to thirty-four percent. One week before, reports surfaced that DeepSeek had quietly opened its first external fundraising round at a ten-billion-dollar valuation, targeting roughly three hundred million dollars. By April 22, with Tencent and Alibaba in talks to participate, the valuation had risen above twenty billion. By early May, the Financial Times reported that the China Integrated Circuit Industry Investment Fund, China’s main state-backed semiconductor investment vehicle and known across the industry as the Big Fund, was in talks to lead the round at a valuation of approximately forty-five billion dollars. The round is structured to sell no more than three percent of equity. Chen Deli, the V4 paper’s lead author, posted publicly on X for the first time the day V4 launched. He was one of only a handful of DeepSeek personnel to do so.
The puzzle is the shape of the company that produced these numbers. DeepSeek is built like a research outfit, not a startup. It has no commercial product. It releases frontier-class models open-weight while every other frontier lab keeps its weights proprietary. It refuses external capital from its founding in July 2023 through April 2026, and the round it has just opened is structured deliberately to limit external influence. Its founder gave one major media interview in July 2024 and has not given another since. Its team is roughly an order of magnitude smaller than the team OpenAI uses to ship models at comparable scale. The company’s response to global attention after the January 2025 release of R1 was, by every visible measure, to keep doing what it had been doing.
The contrast with the rest of the frontier-AI field is sharp. In the same week of April 2026 that DeepSeek shipped V4 with a single Hugging Face upload, OpenAI staged a multi-day product event with embargoed press coverage, partner integrations, and a sequence of executive appearances. Two months earlier, Anthropic publicly accused DeepSeek of using thousands of fraudulent accounts to harvest training data from Claude. OpenAI followed in April with a more specific allegation: an industrial-scale distillation operation involving more than twenty-four thousand fake accounts and over sixteen million interactions. DeepSeek did not respond to either allegation publicly. The company’s posture toward press, toward capital, toward accusations, and toward competition has been consistent: absorb the input, do not change course.
DeepSeek’s shape was built by a decade of compounding forces, sustained by four commitments against the commercial-AI playbook, and is now being tested by three tensions starting to bend the original bet.
DeepSeek exists in the shape it does because of five compounding forces over the decade since its predecessor began trading on GPUs. The first is older than the company itself.
How It Became
The lineage starts with quant trading. In February 2016, Liang Wenfeng and two engineering classmates from Zhejiang University co-founded Ningbo High-Flyer Quantitative Investment Management Partnership. Liang was thirty-one. He had spent the years after graduate school in a cheap flat in Chengdu, applying machine learning to finance after earlier attempts in other fields had failed. By 2013 he was running Hangzhou Yakebi Investment Management. By 2015, Hangzhou Huanfang Technology. The High-Flyer founding was the third attempt at the same problem. On October 21, 2016, the firm began stock trading using a GPU-dependent deep learning model. By the end of 2017, most trading was AI-driven. By 2021, all of it was. In 2019, High-Flyer began constructing its first computing cluster, Fire-Flyer, at a cost of two hundred million yuan: 1,100 GPUs interconnected at 200 gigabits per second. In 2021, Fire-Flyer 2 began construction with a budget of one billion yuan. By 2022 it held five thousand A100 GPUs across six hundred and twenty-five nodes.
In a 36Kr interview in May 2023, Liang explained how the GPU stockpile arrived. “From the earliest single GPU, to 100 GPUs in 2015, 1,000 in 2019, finally 10,000, this happened gradually. But it was mainly driven by curiosity.” The 10,000 figure refers to Nvidia A100 GPUs, acquired before the United States imposed export restrictions on advanced AI chips to China. The acquisition was complete by the time DeepSeek incorporated. High-Flyer also built the surrounding infrastructure: a distributed parallel file system, an asynchronous communication library that replaced parts of Nvidia’s NCCL, a custom neural network operator library, and a distributed training framework. None of this was developed for AI commercialization. It was developed for trading. By the time the AI lab spun out, the compute substrate already existed, fully owned, with no commercial revenue obligation attached. The bottom-up research culture had also already developed: a quant fund without portfolio managers, just servers, and a small team of researchers hired for ability and curiosity rather than experience. On April 14, 2023, High-Flyer announced an artificial general intelligence research lab. On July 17, 2023, the lab spun out as DeepSeek, with High-Flyer as principal investor and backer. Venture capital firms were approached and passed; they considered the company unlikely to generate an exit on a venture timeline.
Compute scarcity shaped what the team built next. By 2023, frontier large language models followed a recipe of more compute, more data, and more parameters. DeepSeek did not have access to that recipe at full scale. Its compute budget was a fraction of the budget OpenAI, Google, and Anthropic could marshal. Liang’s quant-discipline cost calculations made the standard scaling approach economically unsupportable even with High-Flyer’s profits. The team’s response was to invent architectural alternatives that delivered comparable capability at a fraction of the compute. The pattern began with multi-head latent attention, introduced in DeepSeek-V2 in May 2024. The innovation, Liang said in a July 2024 interview, came from a single young researcher’s personal interest. “After summarizing the mainstream evolution patterns of attention architectures, he came up with the idea of designing an alternative. From idea to implementation was a long process. We formed a team and it took several months to make it work.” The same model used a mixture-of-experts variant with shared experts, always activated, alongside routed experts conditionally activated. DeepSeek-Math, released a month earlier, introduced Group Relative Policy Optimization, a variant of Proximal Policy Optimization that became core to subsequent reinforcement-learning training across V2, V3, R1, and V4. DeepSeek-V3, released in December 2024 with 671 billion total parameters and 37 billion activated, completed its final pretraining run on 2,048 H800 GPUs at a total cost of approximately five and a half million dollars. The figure was widely cited and widely misunderstood. It covers the final training run, not the cumulative R&D cost. But the underlying claim is real: the team had built a frontier-comparable model at roughly one-tenth the compute of comparable Western models. The V4 paper, released April 24, 2026, extends the pattern. Its title, “Towards Highly Efficient Million-Token Context Intelligence,” names the architectural orientation explicitly. V4-Pro at one-million-token context requires twenty-seven percent of the single-token inference compute and ten percent of the KV cache size of V3.2. The architectural vocabulary expanded: Compressed Sparse Attention combined with Heavily Compressed Attention, Manifold-Constrained Hyper-Connections strengthening residual signal propagation, and a Muon optimizer for training stability. The lab has built its identity around innovations that compute-rich competitors did not need to invent.
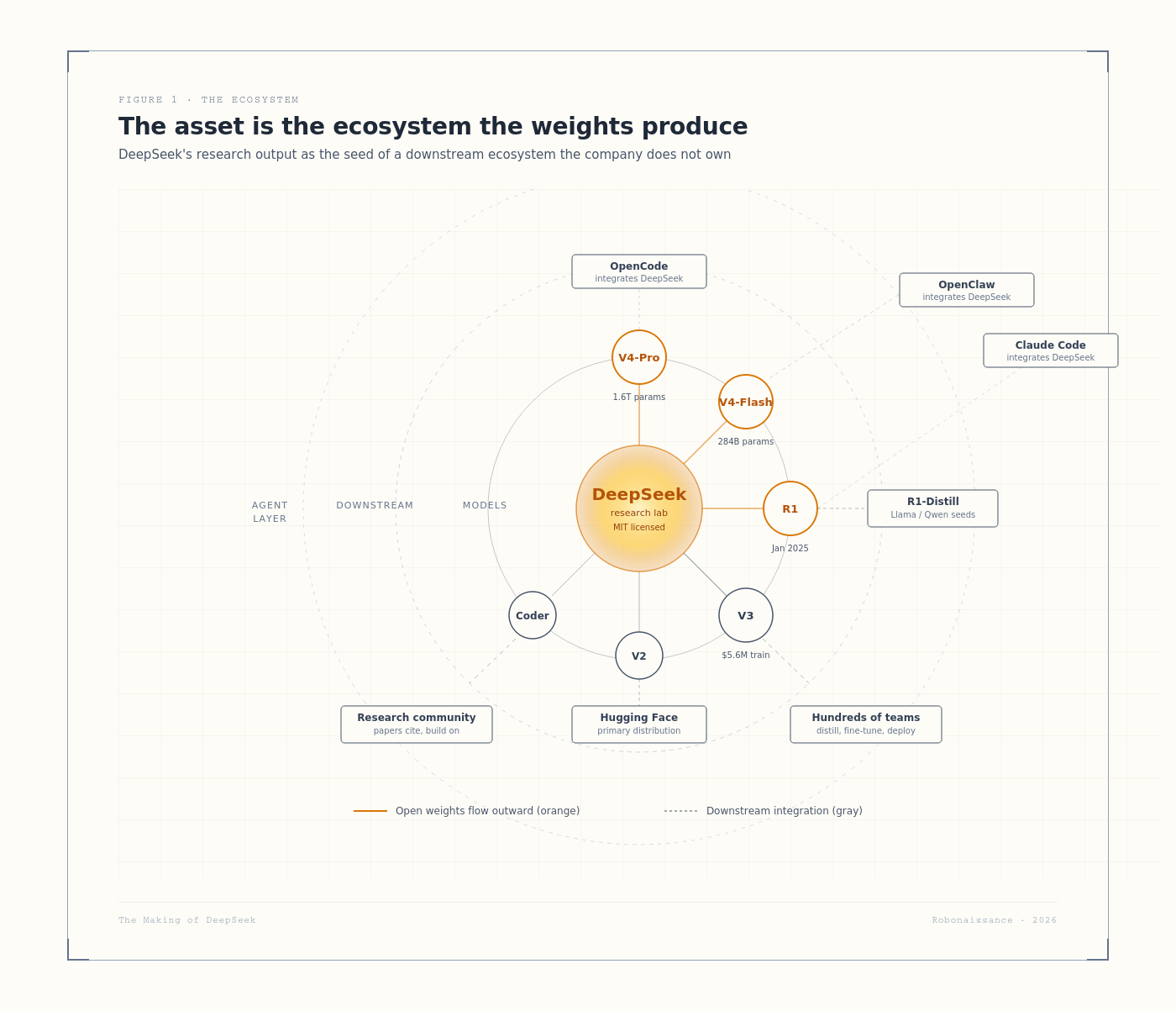
Open weights came next, and stayed. From V1 forward, DeepSeek has released every major model with downloadable weights. DeepSeek Coder in November 2023 was source-available with restrictions; DeepSeek-LLM later that month moved closer to permissive. From V2 in May 2024 onward, every release is MIT-licensed. V3 in December 2024, R1 in January 2025, V3.1 in August 2025, V3.2 in September and December 2025, V4 in April 2026. The pattern is unusual at frontier scale. OpenAI released GPT-2 weights and never released a frontier model openly again. Anthropic was never open. Google DeepMind keeps frontier models closed. Meta is open as competitive strategy against the closed labs. DeepSeek treats openness as research contribution, not as competitive maneuvering. In the July 2024 interview, Liang explained why. “In the face of disruptive technology, the moat formed by closed source is short-lived. Even OpenAI being closed cannot stop others from catching up. So we deposit value in the team. Our colleagues grow in this process, accumulate know-how, form an organization and culture that can innovate, and that is our moat. Open-sourcing and publishing papers, we actually lose nothing. For technical people, being followed is a great achievement. Open source is more of a cultural act than a commercial one. Giving is itself an additional honor.” The downstream effect was an ecosystem. Within weeks of R1’s release, hundreds of teams were running, distilling, and fine-tuning the model. DeepSeek-R1-Distill models seeded from Llama and Qwen base models, fine-tuned on synthetic data generated by R1, multiplied through the open-source community. By V4 launch in April 2026, the agent-layer infrastructure that runs on DeepSeek weights was substantial: Claude Code integrates, OpenClaw integrates, OpenCode integrates. The ecosystem became the company’s actual long-term moat. The open-weights posture was the cause.
Then came January 20, 2025. DeepSeek released R1 at the same time it launched the chat.deepseek.com chatbot for iOS and Android. Within seven days, the chatbot had passed ChatGPT as the number one free application on the United States iOS App Store. Nvidia’s stock dropped eighteen percent in a single day, eliminating six hundred billion dollars of market capitalization, the largest single-day loss in the company’s history. Over a trillion dollars of technology market value evaporated in the same week. Marc Andreessen called the release artificial intelligence’s Sputnik moment. Sam Altman, asked about the model the same week, called the competition invigorating and said OpenAI would speed up its release cadence in response. The Center for Strategic and International Studies, in a contemporaneous analysis, challenged the Sputnik framing on the grounds that Chinese AI labs still depended on United States hardware. The Chinese Academy of Sciences, in its end-of-year retrospective, characterized the release as a clear example of Chinese artificial intelligence development surpassing OpenAI. Both characterizations got something right. The technical achievement was real and was real in the way the Sputnik framing implies: a country whose AI capability had been treated as derivative produced a frontier-comparable model that disrupted Western market assumptions. The hardware-dependence caveat was also real: R1 was trained on H800 GPUs that DeepSeek had acquired through legitimate channels, and the broader Chinese AI infrastructure stack still leaned heavily on Nvidia. What changed for DeepSeek the company in the days after R1 was the environment, not the company itself. International recognition arrived. Commercial pressure followed. Recruitment competition intensified. Geopolitical scrutiny rose. On the day of R1’s release, Liang attended a symposium hosted by Premier Li Qiang in Beijing, where he was asked to provide opinions on a draft of the 2024 government work report. On February 17, 2025, he attended a symposium hosted by General Secretary Xi Jinping at the Great Hall of the People, alongside Ren Zhengfei of Huawei, Jack Ma of Alibaba, and other heads of top Chinese private-sector companies. The two appearances elevated Liang and DeepSeek into nationally significant standing. They also made every subsequent decision a more public one.
The pressure built through 2025. Core researchers departed for better-funded competitors. Luo Fuli left for Xiaomi. Wang Bingxuan left for Tencent on some accounts and ByteDance on others. Wei Haoran and Ruan Chong left. In early 2026, Guo Daya joined ByteDance’s seed team. The 36Kr industry framing was that DeepSeek researchers, watching peers depart for compensation packages they had not been offered, began wondering why not. R2, the planned successor to R1, was delayed multiple times through 2025. Reports cited chip stability issues with Huawei Ascend training and slow data labeling. Liang reportedly was not satisfied with R2’s performance. Through late 2025 and into 2026, domestic competitors narrowed the technical gap within China substantially. Moonshot’s Kimi K2.6 reached one trillion parameters. Zhipu’s GLM 5.1 reached 754 billion. Alibaba’s Qwen and ByteDance’s Doubao both shipped competitive iterations. The Council on Foreign Relations, analyzing V4 in April 2026, concluded that DeepSeek V4 was likely the strongest Chinese model but only narrowly. April 2026 brought a cluster of changes that were difficult to read except as the original posture beginning to bend. April 17 saw the first reports of fundraising at a ten-billion-dollar valuation. April 24 saw V4’s launch, alongside hiring posts for agent research, supercomputing operations, a recruitment manager, comprehensive services HR, a corporate culture director, and an accountant. April 27 saw the equity restructuring that gave Liang a thirty-four percent direct stake, exceeding the one-third threshold required to block special resolutions under Chinese company law. April 29 saw the launch of an image-recognition gray test, signaling multi-modality. By early May, the Big Fund was in talks to lead the round at a forty-five billion dollar valuation. The stated purpose, per 36Kr Investment World, was not cash needs but the establishment of a market valuation benchmark for employee stock options, amid talent-poaching pressure from rivals. The company that had refused external capital for nearly two years was now opening itself, deliberately and at limited scale, to outside investment.
The five forces compounded. Quant lineage gave compute and freedom from commercial pressure. Architecture-over-scale conviction turned constraints into innovations. Open weights stabilized the company’s identity around a developer ecosystem. R1 changed the environment from quiet research lab to global stakes. The 2026 commercial-pressure shift is now bending the original posture in ways that the V4 launch, the equity restructuring, and the first-ever fundraising round all signal at once. The shape DeepSeek has now is the shape these forces produced.
That shape has a specific architecture, a specific operating model, a specific posture toward the field. To understand what DeepSeek is becoming, examine what it has committed to in the way it is built. Each consequential design choice is a commitment to a way of operating that the rest of the field has not made.
The Commitments
Open weights ship at frontier scale
Every major model since DeepSeek-V2 in May 2024 has shipped under MIT License with downloadable weights and an accompanying technical paper. As of late April 2026, V4-Pro at 1.6 trillion total parameters and V4-Flash at 284 billion are both downloadable from Hugging Face. The default in commercial AI labs cuts the other way. OpenAI keeps weights closed at the frontier. Anthropic was never open. Google DeepMind keeps frontier closed. The weights, in the closed-lab framing, are the asset.
DeepSeek’s bet is that the asset is the ecosystem the weights produce, not the weights themselves. R1 was distilled and fine-tuned by hundreds of teams within weeks of release. The R1-Distill seeds derived from Llama and Qwen base models multiplied through the community. By V4 launch, the open agent-layer infrastructure integrated with DeepSeek weights at release-day level: Claude Code, OpenClaw, OpenCode. The downstream ecosystem became the long-term moat. The intellectual move is to treat frontier capability as a property of the field rather than of an organization. Liang’s framing in July 2024 is consistent with this read: the moat formed by closed source is short-lived, and the lab’s actual contribution is the rate at which the field advances.
Release is a research output, not a product
V1 through V4 have shipped as research papers plus weights, not as products. No marketing campaign accompanies a release. No CEO blog post. V4 launched on April 24, 2026 with a Hugging Face upload, a technical report, and a routine update to the API documentation. Liang has not given a press conference for any release. The OpenAI and Anthropic model stages each major release with embargoed coverage, partner announcements, demo applications, and a CEO blog post.
Research-output release gates the company’s energy on research rather than launch. R2 was delayed multiple times in 2025 because Liang was not satisfied with the model’s performance; no launch deadline overrode the research bar. V4 took sixteen months after R1 because the architectural breakthroughs required to ship needed to be done first. Every quarter the team can ship if research is ready and not ship if research is not ready. Release cadence becomes a research-strategy variable, not a market-strategy variable. Most AI companies have these inverted.
The team is small by commitment
Roughly two hundred and seventy R&D and engineering staff as of late April 2026, plus forty-eight in business and compliance. Three hundred and eighteen people total. Most are fresh graduates or hires with one to two years of post-degree experience, recruited heavily from Peking University and Tsinghua University. Division of labor is bottom-up and project-based. Liang, in the July 2024 interview, said: “We don’t have KPIs, and there are no so-called tasks.” Each researcher can call on the training cluster’s GPUs without approval; division of labor across people is determined by interest. The multi-head latent attention architecture that became core to V2 and V3 came from a single young researcher’s personal interest, not a top-down assignment.
The default at frontier AI is the opposite. OpenAI runs roughly three thousand employees. Anthropic runs roughly fifteen hundred. Google DeepMind, six thousand or more. Meta AI is in the thousands. The assumption in the rest of the field is that frontier AI requires a large organization. DeepSeek’s commitment is that small team plus high talent density plus bottom-up culture is enough, and is in some respects better. The contrarian architectural bets get pursued without committee review or roadmap defense. The cost is that key researchers are hard to replace when they leave. The 2025 talent attrition tested this; the V4 paper acknowledgments show R&D turnover under four percent during the V4 development cycle, with ten of two hundred and seventy people departing. OpenAI lost more than a quarter of its key research talents to competitors over the same two-year window. The big-lab structure is not necessary. In some respects it is a constraint.
Commercialization has been refused
Through April 2026, no commercial AI product. No enterprise contracts disclosed. The chat.deepseek.com interface remains free with no subscription tier. Revenue derives exclusively from API usage at deliberately low prices. The V2 pricing in May 2024 triggered a Chinese AI price war that DeepSeek had not intended; in Liang’s account, the pricing was cost-plus, not strategic. The commercial AI lab funding model runs on a different cycle: burn rate sustained by venture capital fundraising, scaled by enterprise contracts, monetized through closed proprietary products. Every Western frontier lab follows some version of this.
Refusing commercialization let DeepSeek concentrate on research output and architecture innovation. No customer success teams. No enterprise sales team. No product roadmap defense to existing customers. Through 2024 and 2025, the operation was sustained by High-Flyer’s quant fund profits. The intellectual move is to treat a research lab as a different kind of organization than a commercial AI company. Most labs in 2026 are commercial AI companies that produce research as a byproduct. DeepSeek inverted the relationship.
This commitment is the one currently bending. The April 2026 fundraising round, the equity restructuring, the new HR and finance roles posted on V4 launch day, the trajectory from a ten-billion-dollar opening valuation to a Big-Fund-led discussion at forty-five billion in two weeks, all suggest the refusal is being qualified rather than maintained absolutely. The first external capital, when it lands, will be the first capital DeepSeek has accepted in nearly two years. The structure of that capital is constrained: no more than three percent of equity, founder-controlled veto, valuation-establishing rather than cash-need. The company has not announced a pivot to commercialization. It has begun preparing for one.
These commitments, together, define DeepSeek’s bet. Each has been vindicated by what the company has shipped over the past two years. Each is also a constraint. Three tensions shape what those commitments are becoming.
What’s Becoming
The chip ladder is the most external of the tensions, and the most outside DeepSeek’s control. Compute access has tightened over time. The earliest acquisition was 10,000 Nvidia A100s, completed before United States export restrictions. V3’s pretraining used 2,048 H800 GPUs, the export-compliant variant of the H100. The Chinese cloud providers serving R1 used the H20, the further-restricted variant. The V4 paper does not disclose training hardware, in a notable departure from the V3 paper’s disclosure. United States government officials have alleged that V4 was trained on Nvidia Blackwell chips smuggled despite export bans, per Reuters reporting in February 2026, follow-up reporting by The Information in April 2026, and Council on Foreign Relations analysis at the V4 release. DeepSeek has not publicly responded to the allegation; Nvidia has called the smuggling claims “farfetched.” Inference for V4, by the lab’s own announcement, has been optimized for Huawei Ascend. On V4 launch day, eight Chinese chip companies completed inference adaptation simultaneously: Huawei Ascend, Cambricon, Hygon Information, Moore Threads, Muxi, Kunlunxin, T-Head Zhenwu, and Daysci. The Cyberspace Administration of China has separately requested that large Chinese corporations stop buying the Nvidia H20 and switch to domestic suppliers. Access keeps tightening; domestic chip viability remains uncertain. Whether DeepSeek can sustain frontier model development on domestic chip alternatives, or whether continued reliance on Nvidia is essential, is the central undecided. The pace of United States and Chinese technology decoupling is the largest variable in DeepSeek’s next two years.
Capital is the next tension, and the most internal. The April 2026 fundraising round is the first external capital DeepSeek has accepted. The structure of the round signals defense rather than concession. Liang took a thirty-four percent direct stake before letting any external investor in. Under Chinese company law, a stake above one-third blocks special resolutions; Liang’s direct holding now exceeds this threshold and gives him veto power over major decisions. The round is structured to sell no more than three percent of equity, capping any single investor’s influence. The composition of investors has shifted in real time. Initial reports in mid-April had Tencent and Alibaba in talks at a ten-billion-dollar valuation. By April 22, the valuation had moved above twenty billion as investor demand rose. By early May, the Financial Times reported that China’s state-backed semiconductor fund, the Big Fund, was in talks to lead the round at approximately forty-five billion dollars. The Big Fund’s involvement specifically changes the strategic shape of the round. Where Tencent and Alibaba would have brought commercial-strategic capital, the Big Fund is the central state vehicle through which Beijing has financed China’s semiconductor industry, and its leadership of the round signals that DeepSeek is now treated as strategically important rather than as a normal venture investment. The historical pattern offers a warning. Every prior open-weights frontier lab eventually closed its weights. OpenAI is the canonical case, having begun open and become closed. The structure of DeepSeek’s first capital raise, with its small percentage and founder-controlled veto, is a deliberate hedge against the trajectory that closed every prior open lab. Whether the hedge holds, and whether it holds against state-backed leadership specifically, is undecided.
The competition is closer to home than it used to be. At R1’s launch in January 2025, DeepSeek had no real Chinese competitor at frontier scale. Sixteen months later the gap inside China has narrowed. Moonshot’s Kimi K2.6 at one trillion parameters, Zhipu’s GLM 5.1 at 754 billion, Alibaba’s Qwen series, and ByteDance’s Doubao all compete on most public benchmarks. V4-Pro Max leads on coding benchmarks, with a LiveCodeBench score of 93.5 and a Codeforces rating of 3206. It trails on knowledge-breadth benchmarks, where Gemini-3.1-Pro consistently leads. The V4 paper itself frames the gap to frontier as approximately three to six months. The competitive economics inside China have shifted further. Better-funded competitors at Alibaba and ByteDance have orders of magnitude more capital and can compete at scale. DeepSeek’s architectural-innovation moat depends on staying ahead at innovation, not at scale. The fundraising round is in part an acknowledgment of this constraint: capital for retention, R&D infrastructure, and employee stock-option valuation, rather than for product or marketing. Whether the architectural lead holds over the next year is the question the round is trying to answer.
DeepSeek made a research-shaped bet at frontier scale. The bet survived its own success. Whether it survives the response to that success is the question the next twelve months answer.
This is the second article in The Making of, a Robonaissance series exploring how AI and robotics systems came to be what they are, and what they are still becoming.