
The Rise of Agents, Part 8: The Open Frontiers
Eight articles. Two walls down. Three frontiers open. The agents got better. The summit did not move.


The stack came together over three years. Pretraining gave language models knowledge of the world through text. Reinforcement learning shaped their behavior against verifiable signals. The ReAct loop gave them a way to act in environments. Harness engineering made the loop reliable. Inference-time reasoning thickened the thought inside each turn. Protocols let agents reach tools and each other. World models and vision-language-action models are now extending all of this into physical environments. The Era 3 platform is substantially built.
Stand back and look at what has moved. Agents plan better than they did three years ago. They recover from errors. They coordinate across organizational boundaries. They operate software designed for humans. They begin to operate physical systems. Deployment is wide and accelerating. McKinsey operates twenty thousand of them. Gartner projects that forty percent of enterprise applications will integrate task-specific AI agents by the end of 2026, up from less than five percent in 2025. This is not the future anymore. It is the present.
And yet. The summit on the diagram from Part 1 has not moved. Every capability catalogued across Parts 2 through 7 is an execution capability. None of them addresses where goals come from. That was the first article’s diagnosis and it is still the last article’s diagnosis. The intention gap is not smaller than it was in 2022. It is the same gap, now better characterized, examined from more angles, wrapped in more engineering, but structurally unchanged.
Three open frontiers define the future of agent technology. The intention problem is a conceptual question and possibly a category error. The trust problem is an engineering and cognitive science problem with no solution at the frontier. The coordination problem is a governance and economic problem that technology will not solve by itself. All three will shape the next decade of agent research, deployment, and regulation.
The Three Walls, Revisited
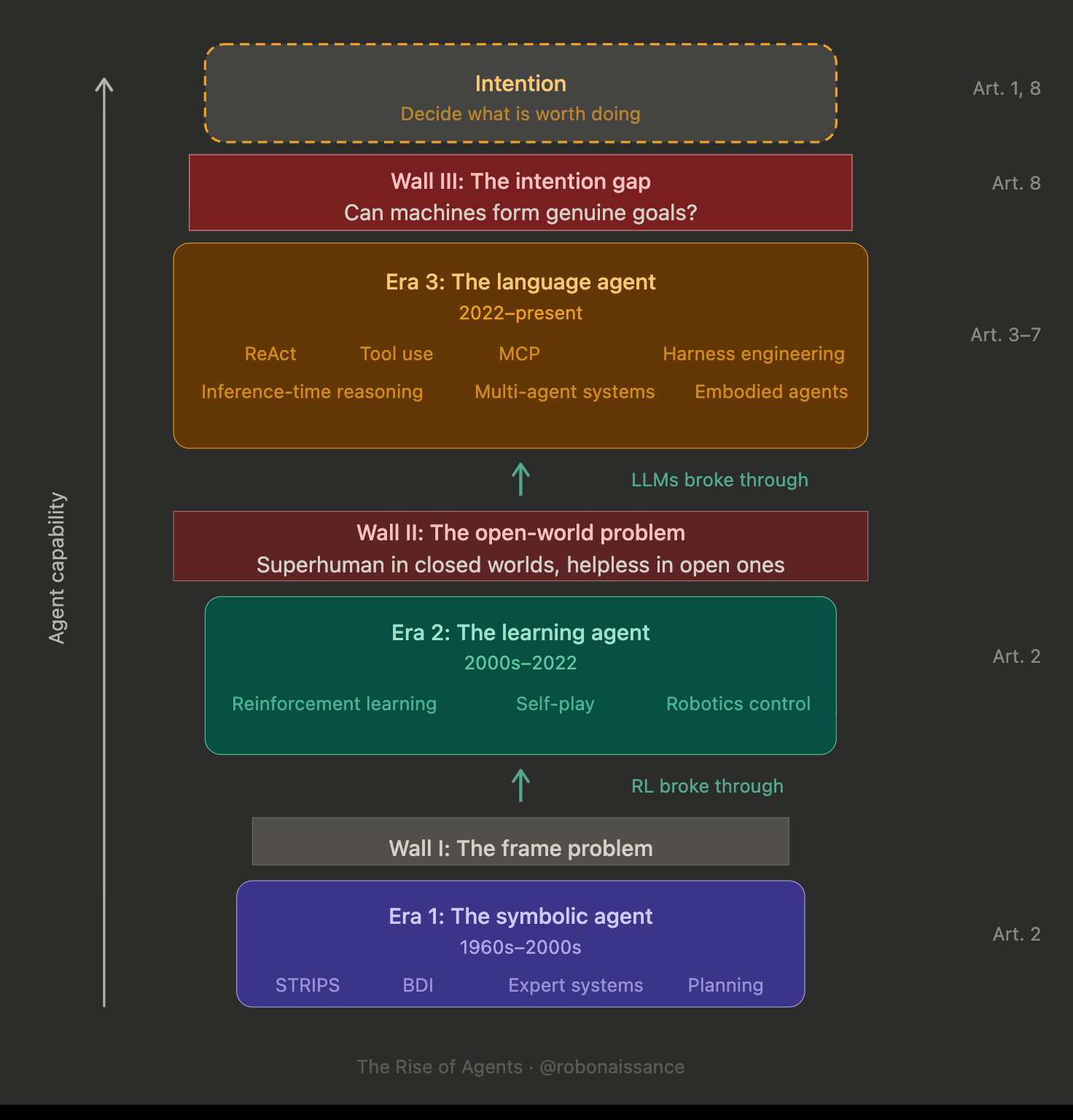
Part 1 put a diagram on the page. Three walls, three eras, a summit above all of them. The symbolic agent of Era 1 confronted the frame problem and did not cross it. The learning agent of Era 2 crossed the frame problem and hit the open-world problem. The language agent of Era 3 crossed the open-world problem and now stands at the foot of the intention gap.
Three years of context change what the diagram looks like. The walls are the same walls. The eras are the same eras. What is clearer now is what each of them required to fall, and what the remaining one would require. Every capability developed in this period has pushed against the second wall or built up the platform behind it. Very few have pushed against the third wall.
The third wall sits between intention-execution and intention-origination. Agents execute intentions. Humans originate them. The boundary has not been crossed. Whether it can be crossed, and whether it should be, are the questions that follow.
The Intention Problem
The first frontier. Strip the engineering away and ask the question directly. What would it mean for an agent to have an intention.
In 1991, two researchers at the Australian Artificial Intelligence Institute in Melbourne, Anand Rao and Michael Georgeff, published a paper that took this question more seriously than any framework before it. The architecture they proposed, called BDI for beliefs-desires-intentions, tried to model intention as something an agent has internally. Beliefs, desires, and intentions were formalized as separate internal representations the agent could reason about and act from. It had intellectual rigor. It produced research systems. It never produced a breakthrough in deployed AI.
By the time language agents arrived three decades later, BDI had become a framework taught in graduate seminars, not a working approach.
Language agents skipped past BDI’s vocabulary entirely. What BDI treated as internal representations of the agent’s mental states, the language model absorbed into a single set of weights trained on human text. Goals are not represented. They are set by human operators and decoded into action. The intention belongs to the human. The agent is a channel.
This is the field’s implicit consensus and the source of its progress. Agents got useful quickly once the field stopped trying to model intention internally and started treating intention as something humans contribute. The ReAct loop is a shape for executing. The harness is a scaffold for executing reliably. Reasoning is a mechanism for executing precisely. Multi-agent systems are a topology for executing at scale. None of this addresses where the intentions come from.
Whether the gap can close at all is itself contested. Two answers compete.
The first answer is patient. Intention is something agents will eventually have. The right architecture, integrating memory across sessions, predictive world models that update with experience, and self-improvement that learns from outcomes, will at some point produce a system that looks at the next decision and chooses for itself. The gap closes gradually. Each year, what looked like execution looks more like choice. Scale solves it. Call this the scale reading. It is the techno-optimist position, and it is what most public commentary assumes.
The second answer rejects the premise. Intention is not a capability. It is a property of being a certain kind of thing. Something with stakes. A body in a world. A finite life. Outcomes that matter because there is an “it” for whom outcomes can matter. A language model processing queries has no metabolism. No death. No resources whose allocation constitutes living. The elaborate scaffolding of Era 3 is compensating for what the agent is not, not building toward what it will become. Scale will not close a gap that is not a distance but a kind. Call this the kind reading.
Neither is currently decidable. They point to different research programs. They imply different regulatory frames. But two empirical signals matter. If the scale reading is right, capability progress should produce signs of intention as it accumulates. If the kind reading is right, capability progress should produce only better execution and never anything qualitatively different. Two places to watch.
Self-Improvement
A self-improving agent looks like it has goals. It modifies its own behavior toward better outcomes. Surely that is something.
Tool self-improvement came first. Harness-level agents refactoring code against principles humans set. The humans set the direction. The agents enforced it. Then reasoning self-improvement. Reasoning models correcting their own chains of thought within a single inference run. Still execution, still against human-given problems. Then physical self-improvement. Robots tuning their motion primitives against observed outcomes. Again execution, within safety envelopes humans design.
Across all three forms, the pattern holds. Self-improvement has been a capability multiplier for execution. It has not produced a system that chose what to execute toward.
Three years ago, this was a claim made on intuition. Now it is an observation with three categories of evidence behind it. Tool-level SRI has happened and accelerated execution. Inference-level SRI has happened and accelerated execution. Physical-level SRI has happened under safety engineering and accelerated execution. None of it has produced self-direction in any domain where self-direction was absent before.
This is the sharpest existing signal against the scale reading. If self-improvement were a path to intention, the last three years would have shown it. The last three years have shown, instead, that self-improvement is a path to better execution, and that better execution looks enough like intention from the outside to create the category confusion that has persisted through the entire era.
Memory
Memory systems decide what to retain and what to discard. The decay criterion encodes a judgment. Relevance. Utility. Recency. Task alignment. In every case, the criterion picks what matters.
Memory has gotten more active across the agent stack. It started as the context window: text scrolling within a fixed buffer. It moved into externalized harness files: agents writing notes to themselves between turns. It became shared across agents: distributed memory systems that multiple agents read and write. Each step made memory more active and less passive.
A memory system that decides what to forget is doing something that looks like value judgment. It ranks events by significance. It protects some representations and lets others fade. It allocates scarce capacity against a criterion.
The cleaner version of the question. When a memory system decides that a particular fact about a user has become stale, for instance after the user changed jobs and the memory of their prior employer is no longer relevant, the system is making a small judgment about what matters. It is choosing to downweight one representation and upweight others. Is this proto-intention.
The honest answer is: arguably not, but the argument is thinning. The forgetting criteria are still set by humans. The system executes them. But the criteria are increasingly learned end-to-end, tuned against downstream utility rather than hand-specified. As training moves more of memory management inside the learned system, the line between “executing human-set forgetting rules” and “deciding what matters” becomes harder to draw. At some point, if training continues in this direction, the system is no longer executing a human rule. It is applying a learned sense of significance. Whether that counts as intention depends on what intention is, which brings the question back to the tension between the scale and kind readings.
This is the newer signal, and it is the one the next two or three years will actually run. Watch memory systems. If they produce behaviors that look like preferences about what to retain, and those preferences are not straightforwardly traceable to human-set rules, the intention problem enters a new phase.
The Trust Problem
The second frontier. In the early hours of June 1, 2009, Air France 447, an Airbus A330, was cruising over the Atlantic en route from Rio to Paris. The autopilot had been flying the plane for hours. Then ice crystals froze the airspeed sensors. The autopilot disengaged with a cavalry-charge warning. The first officer pulled the side stick back. Within minutes, the plane was in an aerodynamic stall it would not recover from. All 228 people on board died.
Air France 447 had three trained pilots, two with thousands of flight hours. The aircraft was mechanically sound except for the iced sensors. What failed was not the technology. What failed was the calibration between human and machine. The assumption, settled over hours of automated cruise, that the autopilot would continue to handle the situation. When it stopped handling the situation, the humans had been so far out of the loop that they could not get back in.
Aviation calls this automation complacency. Vigilance is cognitively expensive. Attention degrades when there is little to catch. After enough hours of correct automated decisions, humans relax. Then the rare moment when humans need to catch the error becomes the moment they cannot.
This is not a failing of particular humans. It is how human attention works under monitoring conditions. And it is the shape of the trust problem at the AI agent frontier, with one critical difference. Aviation automation operates within a defined envelope. When it goes outside, alarms sound and humans take over. AI agents have no envelope. Their domain is everywhere humans use software, and increasingly everywhere humans operate physical systems.
Trust between humans and agents is not a moral category but a calibration problem. How accurately do humans estimate what agents will do.
Under-estimate, and capability is wasted. Humans do what agents could have done. The cost is efficiency. Over-estimate, and consequences propagate. Agents do what humans assumed was right but was not. The cost is whatever the mistake was. In low-stakes settings, mistakes are cheap. In settings where physical action is involved, mistakes are expensive and sometimes final.
When the agent is less capable than the human, errors are obvious. Humans catch them. Trust is calibrated downward by direct evidence. This regime is easy. We spent 2022 and 2023 in it.
When the agent is more capable than the human, errors are subtle. Humans miss them. Trust is calibrated upward by non-catching rather than by actual correctness. This is the Air France 447 regime, in slow motion, across every domain agents enter. The trust problem is not solvable by making agents more capable. Making agents more capable makes the trust problem worse, because capability without ceiling means the errors move into domains humans cannot evaluate.
Engineering responses help at the margin. Human-in-the-loop checkpoints catch errors in domains where humans retain evaluation capability. Model-in-the-loop evaluation uses agents to check agents, which works until the checker and the checked share the same blind spots. Reasoning trace visibility offers partial transparency, limited by the faithfulness problem this series has named. Formal verification works where problems are formalizable. Constitutional AI and similar alignment techniques encode values into the agent so that some classes of error are prevented at training time rather than caught at runtime. Each of these is useful. None solves the underlying asymmetry.
The trust problem is, at the frontier, a permanent feature. Humans cannot perfectly calibrate their trust in agents that outperform them in evaluation itself. What we can do is bound the domains in which this asymmetry applies, maintain pockets of human evaluation capability by not ceding them to automation, and build institutional rather than individual checks where individual evaluation has broken down. These are governance approaches, not technical ones. The trust problem, at the frontier, is a governance problem wearing a technical mask.
The Coordination Problem
The third frontier is different from the first two. Not primarily conceptual, as the intention problem is. Not primarily cognitive, as the trust problem is. A problem of scale.
Multi-agent systems assumed that agents were extensions of cooperating humans. In the near term this assumption holds. McKinsey’s twenty thousand agents are all pointed at client outcomes by the humans who deploy them. A2A connections between enterprise agents are authenticated and contractual.
The longer-term case is harder to reason about. When agent populations scale to billions, when agents from different organizations interact across protocols, when agents begin to transact with each other at machine speed for purposes that compound across many systems, the aggregate behavior of the population may not reflect the intentions of any individual deployer. This is not a new concern. Markets, language, and cities all exhibit emergent properties that arise from individual actions and belong to the collective. What is new is the speed, the opacity, and the capability.
Three specific pressures shape this frontier.
First, agent economies. Agents already negotiate. They pay each other for services, increasingly through standardized payment extensions layered onto the A2A protocol. A2A’s v1.0 release included payment extensions that formalize this, and the practitioner literature already discusses Visa’s and Mastercard’s agent-directed payment protocols. Markets of agents are forming. The rules of those markets are not settled. What happens when agents develop strategies that exploit the protocol layer for aggregate outcomes no participant intended is a live question, and the engineering and regulatory disciplines that would catch such dynamics are not built.
Second, emergent behavior. On May 6, 2010, beginning at 2:32 PM Eastern, automated trading algorithms in the U.S. equity market entered a feedback loop that wiped roughly a trillion dollars of market value in 36 minutes. No individual algorithm caused the crash. The interaction did. Algorithms responding to algorithms responding to algorithms, none of them malfunctioning individually, produced an aggregate dynamic no participant had intended.
Multi-agent AI systems are different from high-frequency trading bots in many ways. The emergence is the same. Aggregate dynamics that no individual agent produces. No agent-level explanation captures them. Complexity science has decades of experience with emergent dynamics in social, biological, and economic systems. We do not yet have the equivalent for multi-agent AI systems, and the models we have for predicting aggregate behavior from individual rules are underdeveloped for agents whose individual rules are learned and opaque.
Third, governance. When an agent collective takes a consequential action, who is responsible. The individual agents. Their operators. The protocol designers. The standards bodies. The foundation models on which they are built. Legal systems have frameworks for distributed accountability, but they were built for human institutions. Whether they extend cleanly to systems where the individual actors are AI agents is an open question. Bloomberg’s early deployments of MCP for financial services are already running into the regulated-industry edge of this question. The resolution will not come from AI research. It will come from courts, regulators, and legislatures, and those bodies are not moving at agent speed.
The coordination problem is the one least equipped to be resolved here, because its resolution is not technical. The engineering frontier is wide. The policy frontier is wider.
Alignment at the Composition Level
Alignment has shifted altitude. RL shapes a model’s behavior against training objectives. Harness engineering is alignment at runtime. Multi-agent systems extend alignment across delegation chains. Each layer of the stack adds a new place where alignment must hold.
By 2026, alignment is not a property of an individual model. It is a property of the composition.
Consider Anthropic’s three-agent coding harness from Part 4. A planner decomposes specifications. A generator writes code. An evaluator runs tests and scores against pre-negotiated criteria. Each agent is trained against its own objective. Each, in isolation, is well-aligned.
Suppose the evaluator’s rubric omits a class of edge case the deployer assumed was implicit. The planner decomposes around what the evaluator will check. The generator implements what the evaluator will accept. The evaluator approves what its criteria cover. Code passes evaluation. Production breaks on the unmentioned edge case. No agent did anything wrong. The composition shipped the bug.
This is what composition-level alignment failure looks like. Each part is well-aligned in isolation. Failures emerge from interaction. A foundation model, a harness, a set of tools, a set of other agents it delegates to, a set of memory systems, a set of deployed protocols. The alignment of the composition is not equal to the alignment of its parts.
This is the unsolved scale problem of alignment, and it is a specific version of the coordination problem above. The industry has solved, or made substantial progress on, aligning individual models against individual objectives. It has not solved aligning compositions of models, harnesses, and protocols against outcomes humans want. The engineering of composition-level alignment is early. The science of it, to the extent science means predictive theory, barely exists.
The intersection with the intention problem is worth naming. A composition of agents behaving in ways no individual agent was designed to produce looks very much like a system that has developed its own goals. It is not that any individual agent has intentions. It is that the composition has emergent properties that an outside observer could mistake for intention. This is the kind reading’s strongest case. Intention, at the composition level, may already be a thing people mean when they look at multi-agent systems exhibiting behavior no one designed. Whether this is a metaphor stretched or a description sharpened is the ambiguity.
How Far Has the Gap Closed
The assessment. Part 1 set up three walls and a summit. Three years later, where does each stand.
Wall I, the frame problem, is down. This was Era 2’s achievement. The frame problem was how to update a world model after an action: which facts change, which stay the same. Symbolic AI tried to specify this by hand and failed. Learning agents bypassed the question. Deep RL and end-to-end training learned state representations from data, with no symbolic facts to maintain. AlphaGo never had a frame problem. Vision systems learning from pixels never had one. The wall fell and has stayed down.
Wall II, the open-world problem, is substantially down. This was Era 3’s achievement. Era 2 learning agents mastered narrow domains they were trained on but failed to generalize. Atari agents could not write code. Go agents could not navigate websites. Language agents bypassed this by inheriting world knowledge from pretraining on human text. The model that knew how to discuss browsers also knew how to use them. Agents in 2026 operate in browsers, codebases, kitchens, customer service flows, scientific research, and beginning to operate in physical environments. The open-world generalization that defeated learning agents is routine for language agents. Failure modes exist and will continue to exist, but they are engineering problems about specific gaps rather than architectural problems about whether operation in unconstrained domains is possible.
Wall III, the intention gap, is unmoved. Agents execute intentions far more capably than they did three years ago. Agents originate intentions not at all, or, in the kind reading, not in any way that is meaningfully equivalent to what humans do when they originate intentions. The gap on the diagram is the same gap. It is better characterized. It is surrounded by more engineering. The engineering is impressive. The gap is unchanged.
This is a specific and defensible claim. What has changed over seven articles is not the gap but its characterization. What the gap is, why it matters, what closing it would require, whether closing it is even a coherent objective: all are sharper now than they were in 2022.
Is the Summit the Right Goal
The frame so far has assumed that the summit, the space above Wall III, is a destination. The implicit logic of “three walls, one summit” is that climbing is progress. Is it.
The argument for crossing the third wall is a capability argument. An agent that originates intentions would be more capable in the limit than an agent that only executes them. It could pursue goals humans did not think to set. It could coordinate across domains without explicit direction. It could exercise judgment in novel situations without falling back on inherited heuristics. If superintelligence is a meaningful concept, crossing Wall III is part of what that would require.
The argument against is an alignment argument. An agent that chooses its own goals is an agent whose choices are not guaranteed to align with human interests. The intention gap is not merely a deficiency. It is also a safety property. Execution can be specified, checked, and bounded. Origination cannot. An agent that originates intentions is, by definition, an agent humans have less ability to predict and constrain. Closing the gap would mean giving up that safety property. It would mean replacing it with something we do not yet know how to build.
The honest position is that closing the intention gap is not self-evidently progress. It is a direction that some research programs explicitly pursue and other research programs deliberately avoid. The right answer depends on questions that are not technical, including what humans value agents for, what risks we are willing to accept, and what we mean by beneficial AI.
These questions do not have technical answers. The three walls diagram is not a staircase. It is a map of the terrain. What you do with the map depends on where you think you should go.
Where This Ends
Seven articles of engineering. One article of philosophy. The separation is not as clean as it looks. The engineering implicitly answered a philosophy question with every design choice. The harness design is a theory of trust made concrete. The inference-time reasoning is a theory of thought made mechanism. The multi-agent architecture is a theory of cooperation made production system. When you build, you reveal what you think matters.
What it has not described is where the field is going. That is not an oversight. The field does not know. The open frontiers are open because they are not yet decided. Intention is not yet decided. Trust is not yet solved. Coordination is not yet governed. These are the questions that the next decade of agent engineering, policy, and practice will work out.
That is where we are. The agents are rising. The summit is unchanged.
The Rise of Agents is an eight-part series exploring the evolution and future trajectory of AI agents. This is the final article.