
Tokenomics, Part 2: The Great Inversion. From Training to Inference.
Training capex was the story for three years. Inference is the story now. The largest pool of AI profit is forming downstream. Where the margin is moving, layer by layer.

In 2023, the AI economy was a story about how much it cost to train a model. By 2026, it is a story about how much it costs to run one. The two are not the same story, and the difference matters more than almost any other structural shift this technology cycle has produced.
A frontier-class large language model in 2023 required hundreds of millions of dollars to train and a few cents of compute to answer each user query. By 2026, training a frontier model costs in the low billions, and the cumulative inference compute spent on serving that model exceeds the training cost within the first year of deployment. For GPT-4 alone, industry analysts estimated that the model accumulated roughly $2.3 billion in inference compute spending between its launch in March 2023 and the end of 2024, approximately fifteen times what the training run cost. The model’s lifetime inference bill will be larger again by the time it is retired.
The single-model picture is dramatic. The industry-aggregate picture lags, because labs continue to invest heavily in training the next generation of models even as inference workloads grow underneath. By compute-hours, inference workloads are projected to approach half of total AI compute usage by 2026, and two-thirds by 2028, with training accounting for the remainder. Capital spending lags compute-hour utilization by roughly two years. Provisioning grid power and building out inference-capable data centers takes that long, but the direction is identical. Industry analysts now describe inference as accounting for eighty to ninety percent of the lifetime cost of a deployed AI system. The “training era” of AI economics, which dominated public attention from 2020 to 2024, was actually a transitional period. The current era is the one that will matter for capital allocation, market structure, and where the durable margin sits.
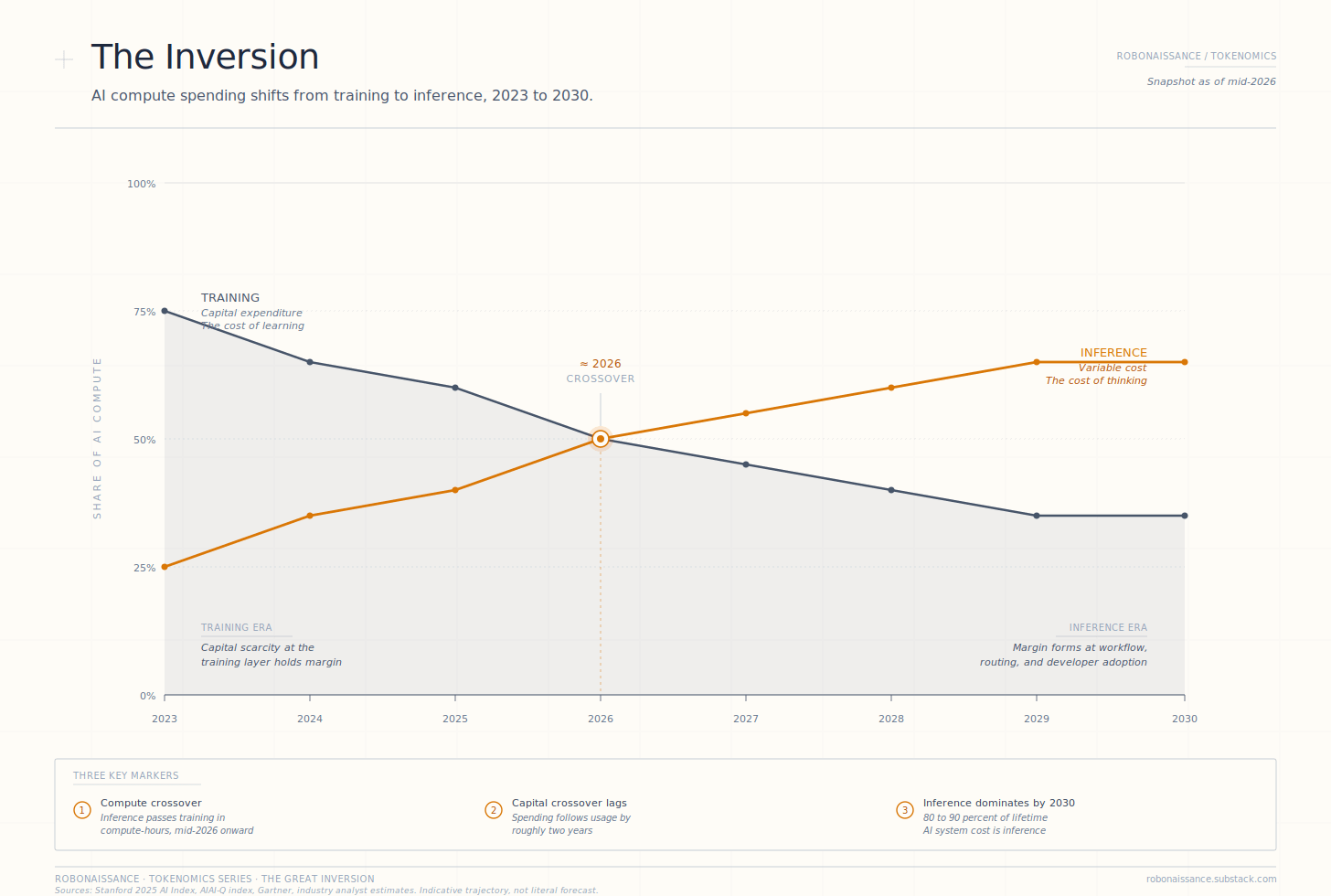
The Inversion. AI compute spending shifts from training to inference between 2023 and 2030. The compute-hour crossover lands in mid-2026; capital spending lags by roughly two years. By 2030, inference is projected to account for sixty-five percent of AI compute and eighty to ninety percent of the lifetime cost of every deployed AI system.
This article reads the inversion through the two frameworks the series introduced in Part 1. The Token Stack tells us which layers are producing the cost. Margin Geography tells us which scarcities are absorbing the value. Together they answer the question the inversion forces every AI company to confront: if the bulk of the spending is moving from training to inference, where is the corresponding pool of profit going to form?
The Training Era and What Made It Scarce
Between roughly 2020 and 2024, the company that could afford the largest cluster of accelerators, recruit the rarest talent in pretraining engineering, and curate the largest corpus of high-quality data was the company whose model led the benchmarks. The binding constraint on capability was the size and quality of the training run that produced a model. Capital, talent, and data were the scarcities that held the margin at the training layer.
The economic logic of that period was straightforward. A training run was a capital expenditure on the order of hundreds of millions of dollars. The economic argument was that the resulting model would then serve users cheaply enough per query that the training investment would amortize over billions of queries, and the company that made the bet would capture the margin on every subsequent one. The closest analog in industrial economics was a fixed-cost asset like a hydroelectric dam: enormous upfront commitment, decades of low marginal-cost output, durable competitive position once built. The argument held at the time. What it underestimated was how large “billions of queries” would actually become, and how much cumulative inference compute would cost at that scale.
This was the logic that justified hundred-billion-dollar valuations for companies whose primary asset was a single trained model. It was also the logic that drove the capital arms race between OpenAI, Anthropic, Google, Meta, and a handful of others, each of which raised funding rounds calibrated to the cost of the next training generation rather than to current revenue.
For three years the logic held. Each generation of frontier model required two to four times the compute of the previous generation, and each generation pushed capability forward in ways that smaller models could not match. The capital scarcity at the training layer was real because the capability gap was real, and the capability gap was real because the training compute ceiling kept moving up.
What Eroded Training Margin
The training era ended, structurally, when the capability gap between frontier closed models and the best open-weight alternatives narrowed faster than the training cost ratio could justify.
The signals accumulated through 2024 and accelerated through 2025. Open-weight releases from Meta, Mistral, Alibaba, and DeepSeek consistently shipped models within months that approximated the capability of frontier closed models released a generation earlier. The cost gap was extreme: DeepSeek’s V3 release in January 2025 reported training costs of approximately five and a half million dollars, less than five percent of what the closest US competitor had spent. Whether or not the exact figure was reproducible, the directional claim was correct. Open-weight competition had compressed the capability premium of a hundred-million-dollar training run to a value that was decreasingly defensible.
Three structural forces drove the erosion. The first was the commoditization of the pretraining recipe. By 2025, the methodology for producing a frontier-class base model was well-documented across published papers, leaked technical reports, and reproduced open-weight implementations. The recipe was no longer the moat. The second was the diffusion of talent. Researchers who had built the early frontier models moved to second-wave labs, open-weight initiatives, and well-funded research groups in China and Europe. The third was the saturation of useful pretraining data. By 2025, every major lab was training on roughly the same corpus of high-quality text and code, with diminishing marginal returns from each additional curated trillion tokens.
The combination meant that capital alone no longer purchased a durable capability lead. A lab could still spend more on training than its competitors, but the resulting model’s advantage period was measured in months rather than years. The scarcity that had held the margin at the training layer was eroding from underneath the largest capital expenditures in private-sector technology history.
Why It Inverted
The inversion was not only caused by training margin eroding. It was caused, in parallel, by inference becoming structurally more valuable than it had been.
The shift was technical before it was economic. Reasoning models, beginning with OpenAI’s o-series in 2024 and accelerating through DeepSeek’s R1 in January 2025, established that an additional dollar spent on inference-time compute frequently produced better outcomes than the same dollar spent on training. Each reasoning query consumes many times the compute of a traditional inference call, sometimes by orders of magnitude, by combining a smaller base model with structured chain-of-thought reasoning, search over candidate solutions, and verification of intermediate steps. The economic structure is fundamentally different from training-time scaling: instead of capitalizing an enormous upfront investment, the cost is paid query by query.
This created two effects. First, it broke the assumption that capability improvements had to come from larger training runs. A small, capable, efficient base model combined with adequate inference-time compute could match or exceed a much larger model run at a single forward pass. Second, it shifted the unit of analysis from model capability to inference economics. The question stopped being “whose model is best” and became “whose serving infrastructure produces the highest quality output per dollar of inference compute.”
The economic implication was the inversion itself. Training, which had been the primary capital expenditure, became one of several capital expenditures, none of which alone secured a competitive position. Inference, which had been the variable cost of serving users, became the layer at which the largest pool of cumulative spending now accumulated.
By the end of 2026, the global AI economy was running on a structure that almost no one had predicted as recently as 2023: the spending lived on the variable-cost side of the ledger, not the capital-cost side.
Margin Geography of the Inversion
The migration is the most consequential value-capture event of this technology cycle. The Margin Geography framework lets us read it precisely.
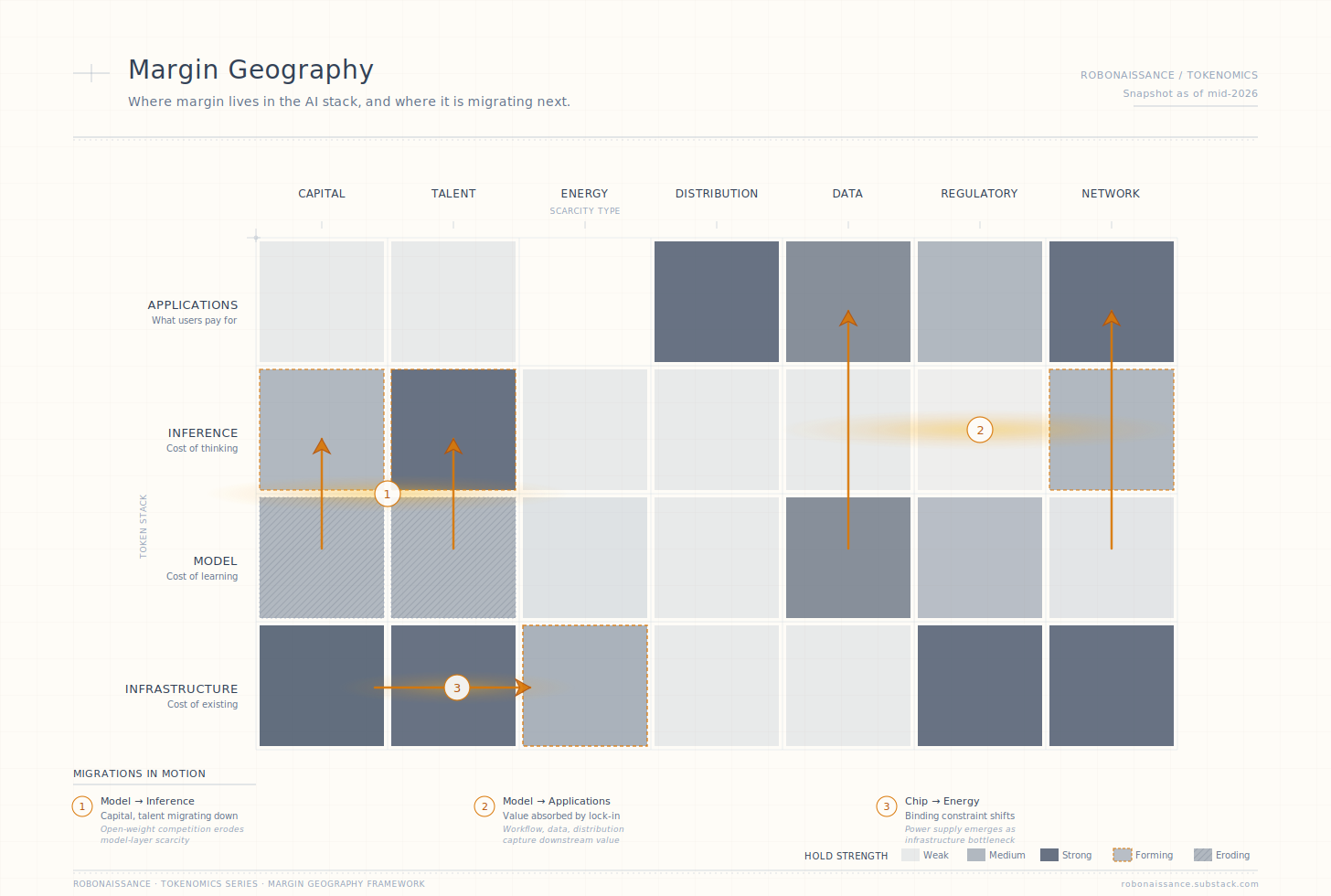
At the training layer, capital and talent are now eroding scarcities. The training run remains expensive, but each additional dollar of training spend now buys a smaller and shorter-lived capability lead. The labs that continue to push the training frontier do so to remain at parity with peers, not to establish a defensible lead. Capital that flows to training in 2026 and beyond is increasingly capital that prevents a fall behind, not capital that wins.
At the inference layer, three scarcities are forming. The first is talent in inference optimization: engineers who can squeeze the maximum quality output per dollar of inference compute through architectural choices, serving infrastructure design, routing logic, caching strategy, and the cumulative thousand small decisions that determine whether an inference dollar produces ten cents of output or a dollar of output. This talent pool is small, recently formed, and concentrated at a handful of companies and labs. The second is capital in specialized inference infrastructure during the buildout phase: data centers designed for inference workloads rather than training workloads, with different memory hierarchies, network topologies, and chip choices. The capital investment to build out this infrastructure is real and currently bottlenecked by both supply and the difficulty of provisioning grid power at the necessary scale. This is a buildout-window scarcity, not a permanent one. Once raw inference capacity catches up to demand, the scarcity will erode the way raw compute capacity in cloud IaaS eroded over the 2010s. The durable margin within the inference layer sits one level above the capacity itself, at the workflow and routing tier that decides what to do with the capacity. The third is a forming network-effect scarcity in developer adoption: the inference platforms that win developer mindshare in 2026 will benefit from accumulating workflow integrations, tool ecosystems, and switching costs that compound over years.
The forming scarcities are exactly what was preview-described in Article 1’s worked example on the inference layer. The eighteen-to-twenty-four-month formation window remains the operative one. Companies establishing positions in inference optimization, infrastructure, and developer adoption before late 2027 will hold those positions for years. Companies attempting to establish them later will not.
What Consensus is Mispricing
The inversion is widely acknowledged in industry discussion. Three aspects of it remain consistently mispriced.
The first is the speed. Capital allocation models still treat inference as a future load and training as the current cost center, even though compute-hour utilization has already crossed the inflection point. The lag between actual usage and reported financials creates a window in which inference-capable infrastructure is being underbuilt relative to where workload will be in two years. The mispricing is straightforward: the market is funding training capacity as if 2024 will continue, while the underlying workload composition has already moved on.
The second is the workload composition asymmetry. Article 1’s multi-dimensional caveat applies directly: not all inference is the same inference. Agent workloads, reasoning workloads, and long-context workloads carry materially different price structures than chat-style inference. Output tokens cost three to ten times what input tokens cost. Cached input is a fraction of non-cached. Agent loops generate high-output, low-cache token compositions that no average price-per-token figure captures. The companies that win at inference are not the companies with the lowest published price-per-token; they are the companies whose serving economics work across the specific workload mixes their customers actually run.
The third is where the durable margin will sit within the inference layer. Public commentary tends to assume that whoever wins inference will be whoever has the largest GPU fleet or the cheapest electricity. The structural reading is different. The lasting margin sits at the workflow tier, where developer integrations, evaluation frameworks, and the routing intelligence that decides which model handles which query become the actual moat. Raw inference capacity will commoditize the way training capacity is commoditizing now. The value will be captured by the tier that decides what to do with the capacity, not by the tier that provides it.
What the Series Will Treat Next
The inversion is the structural event. The Agent Tax, which Part 3 of this series treats next, is what the inversion looks like at the application company’s profit-and-loss statement. Agents are the workload force that bends the inference-layer cost curve upward fastest, because agent tasks consume an order of magnitude more output tokens than the seat-based interfaces they replace. The Agent Tax article unpacks what that means for the unit economics of every application company building on top of inference.
Part 4 treats the open-weight question more deeply: whether open-weight competition continues to compress training margin, what its structural endpoint is, and which layer of the stack captures the released value. Part 5 examines China’s parallel infrastructure stack, where the inversion is playing out under different policy and capital constraints. Parts 6, 7, and 8 deploy the framework across pricing intelligence, the efficiency frontier, and the layer-by-layer Margin Geography that the series has been building toward.
The inversion is happening. Where it goes next, layer by layer, is the question the series is built to answer.
This is Tokenomics, a series that explores the economic physics of the AI era, measured in the unit that runs it all.
Disclaimer: This article is for informational purposes only and does not constitute investment, financial, or legal advice.