
Tokenomics, Part 3: The Agent Tax
Agent tasks consume orders of magnitude more tokens than chat. The inversion lands on application P&L. Gross margin compresses. Where the cost lives, and who absorbs it.

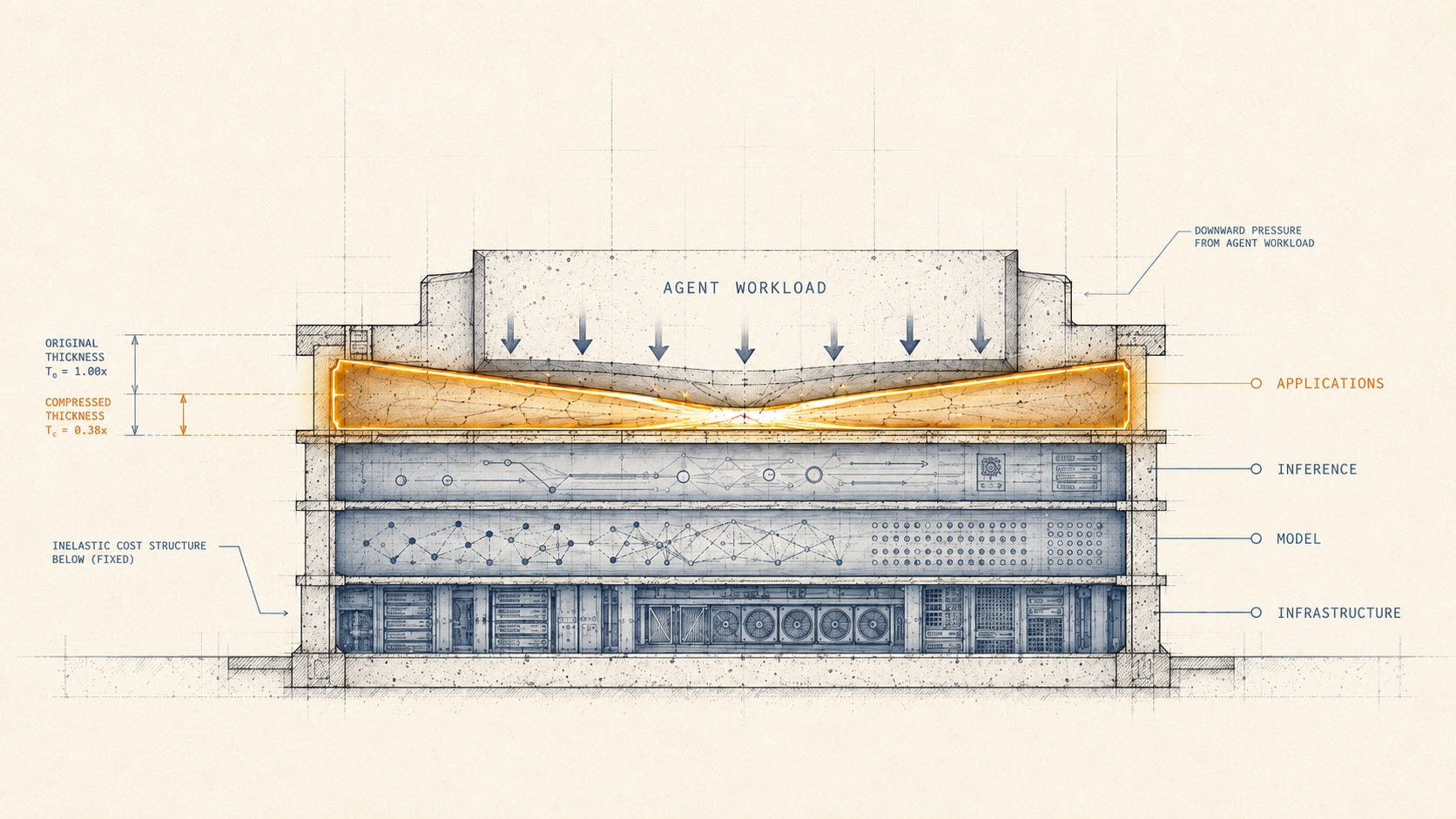
The cleanest place to read the inversion is not a hyperscaler’s earnings call, where training and inference compute are bundled into capital expenditure footnotes. It is the income statement of the application company that has just bolted an agent feature onto a seat-based product. The compression shows up immediately. Cost of revenue rises. Gross margin falls. By the next earnings call, the CFO is disclosing inference cost as a separate line item that did not exist twelve months earlier.
For traditional SaaS companies layering AI on top of existing products, the compression shows up immediately. A typical eighty-dollar-per-month seat, when an AI assistant is added, picks up roughly fifteen dollars of direct variable cost from inference, routing, and supporting infrastructure. Gross margin on that seat drops from eighty percent to closer to sixty-five percent overnight. Across Q4 2025 and Q1 2026 earnings, public SaaS companies disclosing AI-driven margin pressure now name sixty-to-seventy-percent gross margin as the new operating range.
The pattern is sharper for AI-native companies that do not have a non-AI baseline to fall back on. ICONIQ Capital’s January 2026 State of AI snapshot, surveying roughly three hundred AI builders, reported average AI product gross margin at fifty-two percent. The number has improved from forty-one percent in 2024 and forty-five percent in 2025 as companies build inference optimization and routing discipline, but it remains roughly twenty to thirty percentage points below the eighty-percent SaaS standard. The improving trajectory and the structural floor are both real. AI-native companies optimize their way up toward the SaaS norm. They never reach it.
The compression is structural, not cyclical.
This article traces what changes at the application layer when workflows shift from chat to agent. It uses the Margin Geography framework to read where the cost moves, where the customer revenue does not move with it, and which scarcities determine which application companies survive the transition.
What Changes When Workflows Become Agentic
The shift from seat-based interface to agent is not a feature upgrade. It is a token-consumption regime change.
A seat-based chat interaction consumes a few hundred to a few thousand output tokens. The user types a question, the model produces an answer, the transaction completes. Token consumption is bounded by what one human can read and respond to in a session.
An agent task removes that ceiling. The agent reads files autonomously, executes searches, runs terminal commands, iterates on intermediate outputs, verifies results, and retries on failure. Each step generates tokens that the user never directly sees. A typical agent-mode coding task in Cursor reads eight to fifteen files before making a single edit, consuming eight thousand to forty-five thousand tokens on exploration alone, before any code generation begins. Cognition AI’s Devin, operating closer to fully autonomous engineering rather than developer assistance, routinely consumes hundreds of thousands of tokens per task across multi-hour workflows. The user observes one task. The model performs a multi-step workflow underneath.
The token consumption per task has risen by an order of magnitude in the chat-to-agent transition, and by two orders of magnitude in the chat-to-fully-autonomous-agent transition. A workflow that consumed two thousand tokens as a chat interaction in 2023 now consumes twenty thousand as a single-shot agent task in 2025, and two hundred thousand as a multi-step autonomous agent task in 2026. The per-task token consumption climb is not linear. It is compounding.
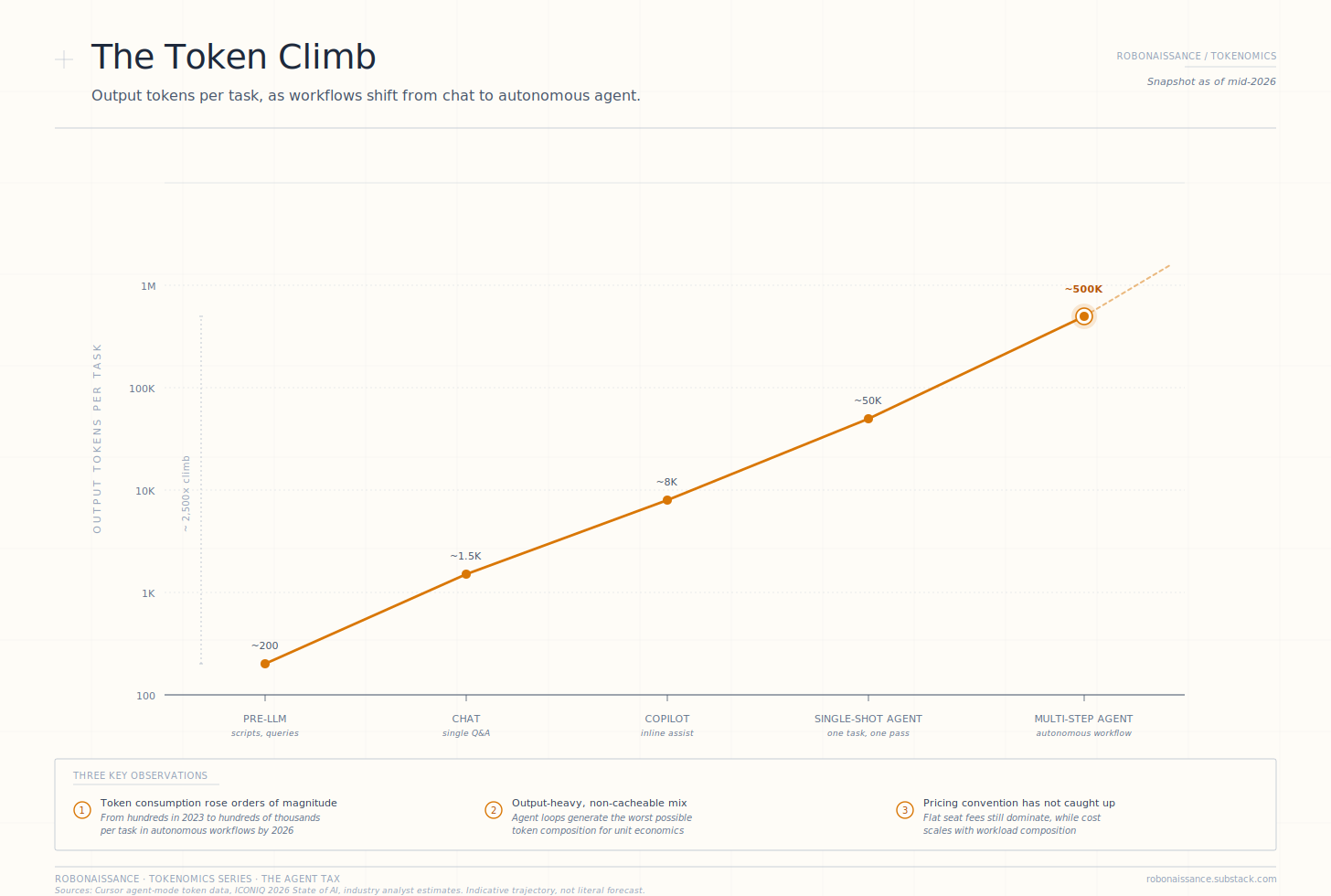
The Token Climb. Output tokens per task across workflow generations from pre-LLM scripts through multi-step autonomous agents. The vertical axis is logarithmic. Token consumption per task has climbed by approximately three and a half orders of magnitude in the chat-to-autonomous-agent transition, a structural shift that no per-seat pricing convention can absorb without gross margin compression.
The economic mechanism is straightforward. Output tokens cost three to five times what input tokens cost on the same model. Agents are output-heavy by structure: they generate reasoning traces, intermediate outputs, tool-call arguments, verification steps. Caching helps with the input side. It does not help with the output side. Agent workflows produce the worst possible token mix for application-company unit economics: high-volume, output-heavy, non-cacheable.
This is the cost-side mechanics. The revenue side has not moved correspondingly.
The Cost Structure of an AI Application Company
The seat-based pricing convention came from the SaaS era, when marginal cost per seat approached zero and a flat monthly subscription captured value efficiently. The convention persisted into the first wave of AI applications. Eighty dollars per month for the seat, with AI features bundled.
The convention fails on agent workloads.
A heavy agent user can consume thousands of dollars of inference compute per month against a hundred-dollar seat fee. The variance across users is extreme. Light users may consume single-digit dollars of compute. Heavy users routinely consume two to three orders of magnitude more. Average pricing fails when the distribution is power-law shaped. The company either prices for the heavy user, pricing out the light user, or prices for the light user, losing money on the heavy user, or prices in the middle, losing money on the heavy users and capturing too much from the light ones.
The cost structure of an AI application company in 2026 decomposes into layers that no SaaS finance template captures. Inference compute averages roughly twenty-three percent of revenue at scaling-stage AI B2B companies across ICONIQ’s surveyed cohort. Supporting infrastructure, including vector databases, retrieval systems, and routing layers, adds materially on top. The combined AI cost of revenue is materially higher than the historical SaaS hosting cost, and it scales with usage rather than with seats.
The token-mix asymmetry compounds the problem. Application companies running agent workloads do not get to choose their token composition. The workload determines it. A coding agent reads orders of magnitude more context tokens than the code tokens it generates. A research agent processes thousands of tokens of source content for every paragraph of analysis produced. A scheduling agent evaluates context many times larger than the calendar actions it outputs. None of these workflows have favorable caching profiles. None of them have favorable input-to-output ratios.
The inversion at the compute layer becomes the agent tax at the application layer. Every dollar that the inversion moved from training capex to inference variable cost arrives in the application company’s cost of revenue.
Three Strategic Responses
Application companies that have run into the agent tax in 2025 and 2026 have converged on three response strategies, each with its own trade-offs.
The first is to shift the customer to consumption pricing. The seat fee shrinks or disappears. The customer pays for what they use, denominated in credits, queries, or tasks. Cursor’s June 2025 pricing overhaul moved exactly this way: a flat Pro tier was replaced by a credit pool that depletes against actual API rates per request. The advantage is that gross margin stops swinging with workload composition. The disadvantage is that the customer experience changes. Customers lose predictability. Light users feel they are subsidizing nothing and start to leave. Heavy users feel surprise bills and start to economize. Both behavioral responses compress revenue growth.
The second is to absorb the cost. The seat fee stays flat. The customer experience stays familiar. The application company carries the variable cost on its income statement and accepts gross margin compression. This is the default response for companies whose primary metric is annual recurring revenue rather than gross margin. ARR keeps growing. The income statement narrative gets harder to sustain over multiple quarters as inference cost as a percentage of revenue rises and gross margin descends from eighty to sixty-five to fifty percent. Eventually the public market or the next funding round prices the compression in.
The third is to vertically integrate the inference stack. Build proprietary inference infrastructure, train or fine-tune in-house models, route the easy queries to cheap open-weight models and the hard queries to frontier APIs. This is the strategy that mature AI companies are pursuing in parallel with the first two. Anthropic and OpenAI pursue it at the model-provider level, building dedicated inference infrastructure optimized for their own model families. At the application level, the same logic appears as routing intelligence: companies like Cursor, Harvey, and Glean increasingly maintain proprietary evaluation harnesses, custom routing layers, and selective in-house fine-tuning to reduce the cost of serving each customer query. The capital investment required to pull it off is substantial. The talent pool of people who can build a production inference stack is small. The companies that succeed will hold a structural cost advantage over their pure-API-integrator competitors. The companies that fail will have spent twelve months on infrastructure that did not work and lost the formation-phase window during which positions in the application layer were available.
Most application companies in 2026 are running combinations of all three strategies. The pure plays at each end of the spectrum are rare. The combinations are messy on the income statement but reflect the reality that no single strategy currently solves the agent tax cleanly.
Margin Geography of the Agent Tax
The application layer reads as the most contested layer in the Margin Geography of the AI economy in 2026, because three things are happening simultaneously. The cost of serving the customer is rising. The willingness of the customer to pay more is uncertain. The structural defensibility of any particular application company’s position is being tested in real time.
Three scarcities are forming at the application layer through the agent transition. They protect gross margin through two distinct financial mechanisms.
Two operate on the cost side. Workflow design talent reduces the compute spent per unit of customer value delivered. Engineers and designers who understand both the user-facing workflow and the underlying token-consumption economics can produce applications that capture meaningful value per token of inference. This talent pool is small, recently formed, and currently distributed across a handful of high-growth AI-native companies. Evaluation infrastructure reduces the compute bill systematically. Application companies that can measure agent task quality empirically, attribute cost per task, and route workloads to the cheapest model that meets the quality bar capture compounding margin advantage. The infrastructure to do this at scale exists at perhaps a dozen companies in 2026.
The third scarcity operates on the revenue side. Integration depth into customer workflows does not reduce the inference cost, but it sustains the customer’s willingness to pay for it. Applications embedded so deeply into customer business processes that the customer cannot disaggregate the AI feature from the rest of the delivered value can pass higher prices through without losing the seat.
Two scarcities are eroding. Raw API access to frontier models is no longer a competitive moat. By 2026, every application company can integrate the same set of models on roughly the same terms. Generic prompt engineering is similarly commoditized: the techniques are documented, the prompts are reproducible, the differentiation has migrated upstream into workflow design and downstream into evaluation infrastructure.
The durable margin within the application layer sits at the intersection of integration depth and evaluation discipline. Revenue-side defense without cost-side discipline becomes a premium-priced product that still loses money on heavy users. Cost-side discipline without revenue-side defense becomes a cheaply-served product that competitors can match. Both sides are required to hold gross margin through the transition. The pattern is clearest in vertical AI applications. Harvey’s embedment into legal workflows, Glean’s enterprise search integration, and Sierra’s customer-service workflow positioning all illustrate the integration-depth scarcity. The contrast is visible too. Horizontal AI feature overlays bolted onto general-purpose software illustrate the strategy that does not protect margin through the agent tax. The AI capability is undifferentiated from competitors. The customer relationship is mediated by the underlying platform. Companies that win deep workflow integration with a specific customer category, and that build the evaluation infrastructure to operate efficiently within that category’s economic constraints, will capture the application-layer margin pool. Companies that compete on generic AI features layered onto generic seats will see their gross margins compress to the point where the unit economics no longer support continued operation.
This is a formation-phase scarcity reading. The application layer is in its margin-formation window in 2026 and 2027. By 2028, the positions will largely be settled.
What Consensus is Mispricing
The agent tax is widely acknowledged in industry conversation. Three aspects of it remain consistently mispriced.
The first is the speed of the transition. Public market analysts are still applying SaaS gross-margin multiples to AI-native ARR. The new operating range is sixty to seventy percent, not eighty to ninety percent, and the implied valuation compression has not yet flowed through analyst models. Companies that grew their ARR fast in 2024 and 2025 by absorbing the agent tax are about to discover that their next funding round or earnings call prices the gross margin reality.
The second is the divergence between AI Supernovas and AI Shooting Stars. Bessemer’s framing of the AI-native company cohort separates the explosive-growth, thin-wrapper companies running around twenty-five percent gross margins from the disciplined, infrastructure-mature companies running closer to sixty percent. The two groups are often valued similarly because their top-line growth rates look comparable. The unit economics are not comparable. The Shooting Stars will compound. The Supernovas will compress when growth slows and the inference bill cannot be outrun with new ARR.
The third is the layer location of the durable margin. The application layer is widely assumed to be the safest place to invest in AI, because it captures the customer relationship. The structural reading is more nuanced. The application layer captures the customer relationship, but the customer relationship alone does not protect against the agent tax. The application companies that survive the transition will be the ones that built integration depth and evaluation infrastructure before the formation window closed, not the ones that won the early customer acquisition race.
What the Series Will Treat Next
The agent tax is the application-layer manifestation of the inversion. Part 4 of this series turns to the open-weight question more deeply: whether open-weight competition continues to compress training margin, what its structural endpoint is, and which layer of the stack captures the value released by training-layer commoditization. The agent tax connects to the open-weight question directly, because open-weight inference is one of the few mechanisms that materially relieves the cost pressure on application companies. Part 5 examines China’s parallel infrastructure stack, where the agent tax is playing out under different policy and capital constraints, and where vertical integration of the inference stack is being attempted at the national rather than the company level. Parts 6, 7, and 8 deploy the framework across pricing intelligence, the efficiency frontier, and the layer-by-layer Margin Geography that the series has been building toward.
The agent tax is the inversion’s application-layer reckoning. Where the inversion lands next, layer by layer, is the question the series is built to answer.
This is Tokenomics, a series that explores the economic physics of the AI era, measured in the unit that runs it all.
Disclaimer: This article is for informational purposes only and does not constitute investment, financial, or legal advice.